AlphaZeroで学習したモデルと人間で対戦するゲームを作成します。
必要なパッケージをインポートします。
1 | # パッケージのインポート |
学習したベストプレイヤーのモデルを読み込みます。
1 | # ベストプレイヤーのモデルの読み込み |
ゲームUIのクラスを定義します。
メソッドは下記のとおりです。
- init ゲームUIを初期化します。
- turn_of_human 人間のターンを実行します。
- turn_of _ai AIのターンを実行します。
- draw_piece 石の描画を行います。
- on_draw 描画の更新を行います。
初期化処理ではゲーム状態と行動選択を行う関数を生成し、キャンバスを用意します。
1 | # ゲームUIの定義 |
人間のターンの処理は下記のようになります。
- ゲーム終了時はゲームを初期化状態に戻します。
- 先手でないときは操作不可とします。
- クリック位置を行動に変換します。
- 合法手でないとき無処理とします。
- 次の状態を取得します。
- AIのターンへ遷移します。
1 | # 人間のターン |
AIのターンは下記のようになります。
- ゲーム終了時は無処理とします。
- ニューラルネットワークで行動を取得します。
- 次の状態を取得します。
1 | # AIのターン |
石の描画を行います。
1 | # 石の描画 |
描画を更新します。全てのマス目と石を描画します。
1 | # 描画の更新 |
ゲームUIを実行します。
1 | # ゲームUIの実行 |
対戦状況は下記の通りです。
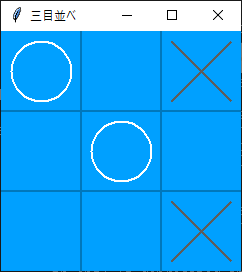
何回か対戦してみましたが、それほど強いイメージはありませんでした。
参考
AlphaZero 深層学習・強化学習・探索 人工知能プログラミング実践入門 サポートページ