AlphaZeroの学習サイクルを実装します。
これまで実装したコードを次の手順で実行していきます。
- デュアルネットワークを作成します。
- セルフプレイを実行します。
- パラメータ更新部を実行します。
- 新パラメータ評価部を実行します。
- ベストプレイヤーを評価します。
2~5を10回(10サイクル)実行します。
では実装に移ります。
まずは必要なパッケージをインポートします。
1 | # パッケージのインポート |
デュアルネットワークを作成します。
すでにベストプレイヤーのモデル(model/best.h5)がある場合は無処理となります。
1 | # デュアルネットワークの作成 |
学習サイクルを10回(10サイクル)繰り返し実行します。
1 | for i in range(10): |
10サイクルの学習を完了するまでは、Corei5・メモリ8GB・GPUなしのPCで10時間ほどかかりました。
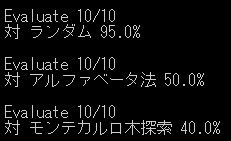
何回か学習サイクルを実行し、ベストプレイヤーの評価を行った結果は下記の通りです。
| 10サイクル | 20サイクル | 30サイクル |
|---|---|---|
 |
 |
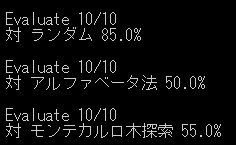 |
学習サイクルを増やすほど各勝率が増えていくかと予想していたのですがそうでもないようです。
ただ最強ロジックのアルファベータ法と互角に勝負できているのでAlphaZeroという手法は秀逸だと思います。
参考
AlphaZero 深層学習・強化学習・探索 人工知能プログラミング実践入門 サポートページ