AlphaZeroの新パラメータ評価部を作成します。
ベストプレイヤー(model/best.h5)と最新プレイヤー(model/latest.h5)を対戦させて、より強い方をベストプレイヤーとして残します。
まず必要なパッケージをインポートします。
1 | # ==================== |
パラメータを準備します。
ボルツマン分布の温度パラメータはバラつきに関するパラメータになります。
1 | # パラメータの準備 |
最終局面から先手プレイヤーのポイントを返す関数を定義します。
1 | # 先手プレイヤーのポイント |
1ゲームを最後まで実行して、先手プレイヤーのポイントを返す関数を定義します。
1 | # 1ゲームの実行 |
最新プレイヤーをベストプレイヤーに置き換える関数を定義します。
1 | # ベストプレイヤーの交代 |
ネットワークの評価を行う関数を定義します。
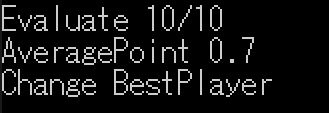
最新プレイヤーとベストプレイヤーのモデルを読み込み、10回対戦させます。
勝率が高い方をベストプレイヤーとして保存します。
1 | # ネットワークの評価 |
動作確認のための実行コードを実装します。
1 | # 動作確認 |
実行結果は下記の通りです。
参考
AlphaZero 深層学習・強化学習・探索 人工知能プログラミング実践入門 サポートページ