1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
| import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_digits
from sklearn.metrics import classification_report
from sklearn.metrics import accuracy_score
from tensorflow.python import keras as K
dataset = load_digits()
image_shape = (8, 8, 1)
num_class = 10
y = dataset.target
y = K.utils.to_categorical(y, num_class)
X = dataset.data
X = np.array([data.reshape(image_shape) for data in X])
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33)
model = K.Sequential([
K.layers.Conv2D(
5, kernel_size=3, strides=1, padding="same", input_shape=image_shape, activation="relu"),
K.layers.Conv2D(
3, kernel_size=2, strides=1, padding="same", activation="relu"),
K.layers.Flatten(),
K.layers.Dense(units=num_class, activation="softmax")
])
model.compile(loss="categorical_crossentropy", optimizer="sgd")
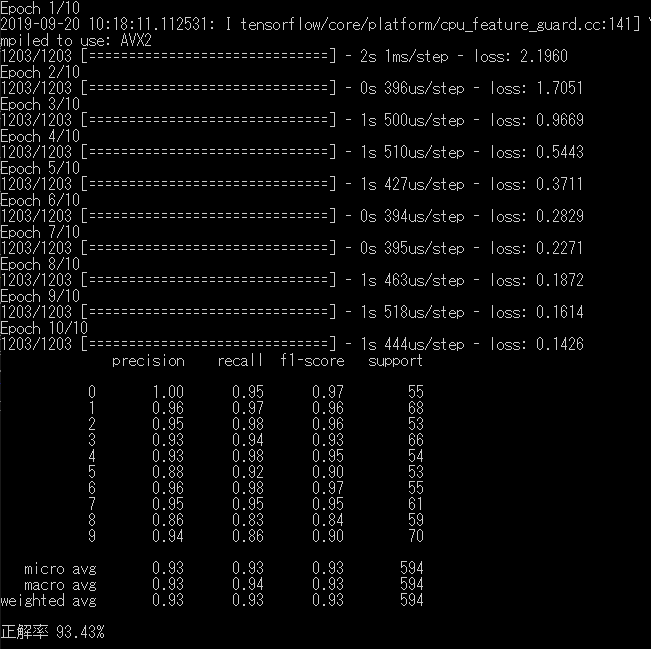
model.fit(X_train, y_train, epochs=10)
predicts = model.predict(X_test)
predicts = np.argmax(predicts, axis=1)
actual = np.argmax(y_test, axis=1)
print(classification_report(actual, predicts))
print('正解率 {:.2f}%'.format(accuracy_score(actual, predicts) * 100))
|