これまではQ[s][a]というテーブル内の値を更新することで学習していましたが、今回からは関数のパラメータを調整することで学習していきます。
まずはTensorFlowで1層のニューラルネットワークを実装してみます。
入力(x)は2行1列の座標、出力(y)は行動価値4行1列を想定しています。
対応する重み(weight)は4行2列でバイアス(bias)は4行1列となります。
1 | import numpy as np |
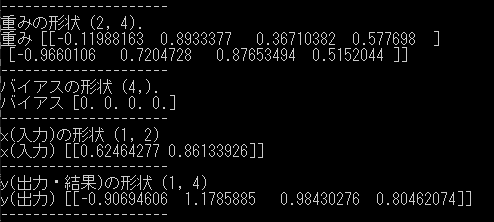
想定した行列とは全て逆の結果となりました。
これは座標を1行2列で入力したためです。=> np.random.rand(1, 2)
このため重み、バイアス、出力の全てが行列が反対になってしまっていますが、本質的な結果は変わりません。
多くの深層学習フレームワークでは行をデータ数(バッチサイズ)を表すのに使うため、このような仕様となっていますので慣れてしまいましょう。
参考
Pythonで学ぶ強化学習 -入門から実践まで- サンプルコード