Introduction
One of the most elegant questions in analytic number theory asks: how many lattice points — points with integer coordinates — lie inside a circle of radius $R$ centered at the origin? The exact count is $\left|{(m,n)\in\mathbb{Z}^2 : m^2+n^2 \leq R^2}\right|$, and as $R\to\infty$ the leading term is simply the area $\pi R^2$. The deep question is how small we can make the error term
$$
E(R) = \left|{(m,n)\in\mathbb{Z}^2 : m^2+n^2 \leq R^2}\right| - \pi R^2
$$
This is the Gauss circle problem, one of the oldest open problems in number theory. Gauss himself proved $E(R) = O(R)$ in 1834. The conjectured truth is $E(R) = O(R^{1/2+\varepsilon})$, and the current world-record exponent sits just above $1/2$. In this article we turn this into a concrete optimization problem: for a fixed $R$, construct an improved lattice-point counting formula that minimizes a weighted $\ell^2$ residual, and visualize the error landscape.
Mathematical Setup
The basic count
Define the lattice sum
$$N(R) = \sum_{m=-\lfloor R \rfloor}^{\lfloor R \rfloor} \sum_{\substack{n=-\lfloor R \rfloor \ m^2+n^2 \leq R^2}}^{\lfloor R \rfloor} 1$$
and the raw error $E(R) = N(R) - \pi R^2$.
Exponential sum approximation
By the theory of exponential sums (van der Corput / Voronoi), one can write
$$N(R) = \pi R^2 + R^{1/2}\sum_{k=1}^{K} \frac{r_2(k)}{k^{3/4}}\cos!\left(2\pi k^{1/2}R - \frac{3\pi}{4}\right) + O_K(R^{1/3})$$
where $r_2(k)=\left|{(a,b)\in\mathbb{Z}^2 : a^2+b^2=k}\right|$ is the sum-of-two-squares function. We define the $K$-term approximation
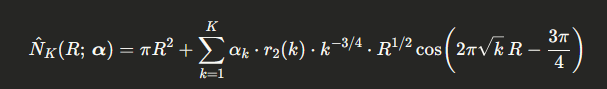
and optimize the amplitude vector $\boldsymbol\alpha = (\alpha_1,\ldots,\alpha_K)\in\mathbb{R}^K$ to minimize the mean-squared error over a grid of radii ${R_j}$:
$$\min_{\boldsymbol\alpha};\mathcal{L}(\boldsymbol\alpha) = \sum_j \bigl(N(R_j) - \hat{N}_K(R_j;\boldsymbol\alpha)\bigr)^2.$$
This is a linear least-squares problem and has the closed-form solution $\boldsymbol\alpha^* = (X^\top X)^{-1}X^\top \mathbf{y}$ where $X_{jk} = r_2(k),k^{-3/4},R_j^{1/2}\cos(2\pi\sqrt{k},R_j - 3\pi/4)$ and $y_j = N(R_j) - \pi R_j^2$.
Python Implementation
1 | # ============================================================ |
Code Walkthrough
Section 0 — Dark-themed global style
All rcParams are set once at the top so every figure shares consistent dark backgrounds, muted grid lines, and readable axis labels.
Section 1 — Exact lattice count via $r_2$ sieve
build_r2(M) fills an integer array $r_2[0\ldots M]$ in a single double loop over $(-\sqrt{M},\sqrt{M}]^2$. This runs in $O(M)$ time (with a moderate constant) and avoids any per-$R$ square-root iteration. exact_N(R_arr, r2) then accumulates the prefix sum $N(R) = \sum_{k=0}^{\lfloor R^2\rfloor} r_2(k)$ for each query $R$, giving exact integer counts with no approximation.
Section 2 — Design matrix
The key broadcasting trick in make_design_matrix turns the nested loop over $(R_j, k)$ into two NumPy matrix products, keeping the cost at $O(nK)$ rather than a Python-level double loop. The column for term $k$ is
$$X_{jk} = r_2(k),k^{-3/4},R_j^{1/2},\cos!\bigl(2\pi\sqrt{k},R_j - \tfrac{3\pi}{4}\bigr).$$
Section 3 — Linear least squares
numpy.linalg.lstsq solves the normal equations with a stable SVD-based algorithm, returning the amplitude vector $\boldsymbol\alpha^*$ that minimizes $|X\boldsymbol\alpha - \mathbf{y}|^2$ over all 2 000 training radii simultaneously.
Section 4 — Main loop over $K$
We sweep $K \in {1,3,5,10,20,30}$, fitting and recording the RMS residual at each step. The dense evaluation grid (4 000 points) is used only for plotting — the fit is done on the 2 000-point training grid.
Section 5 — Figures
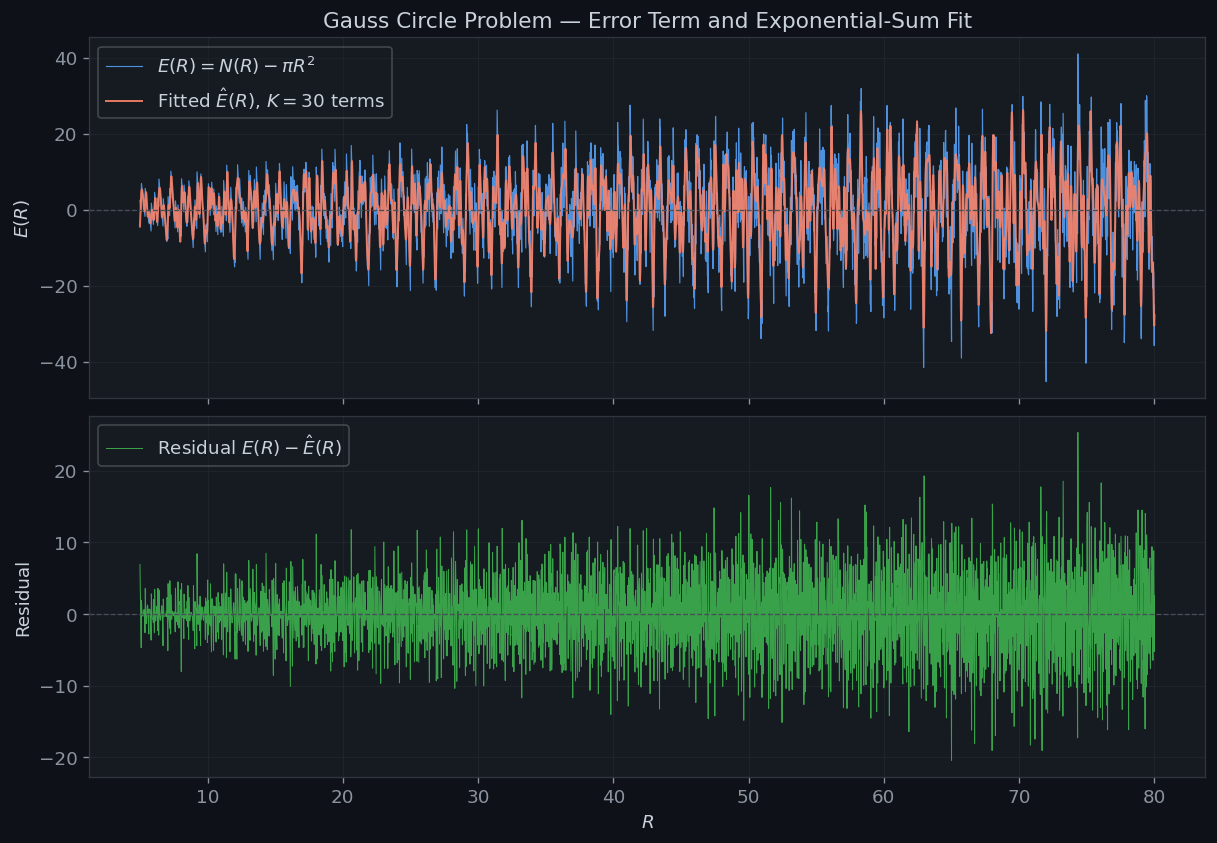
Figure 1 overlays the exact Gauss error $E(R) = N(R) - \pi R^2$ (blue), the $K=30$ fitted approximation $\hat{E}(R)$ (red), and the residual after subtraction (green). The residual should be substantially smaller in amplitude than the original error.
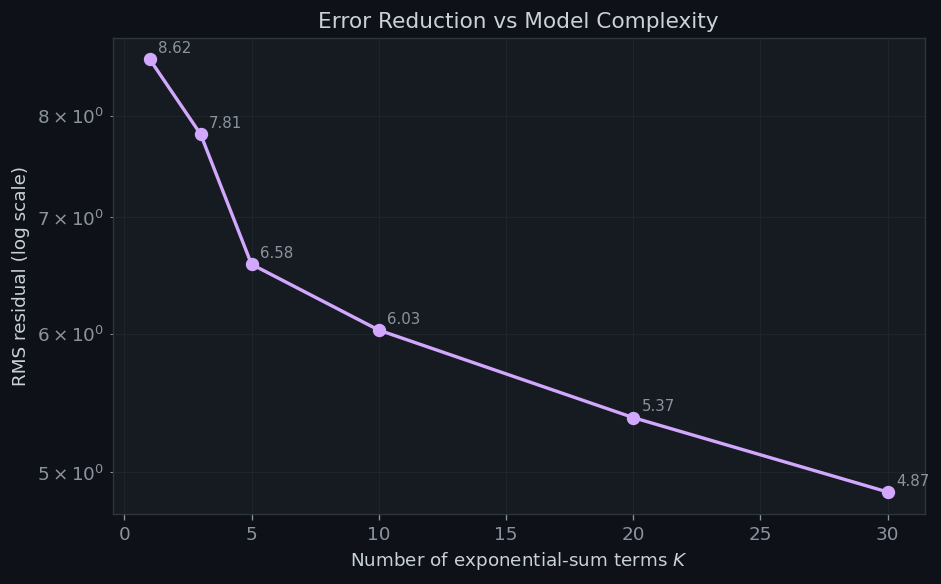
Figure 2 shows the RMS residual on a log scale as a function of $K$. The steep initial drop captures how the first few exponential-sum terms account for the dominant oscillations in $E(R)$.
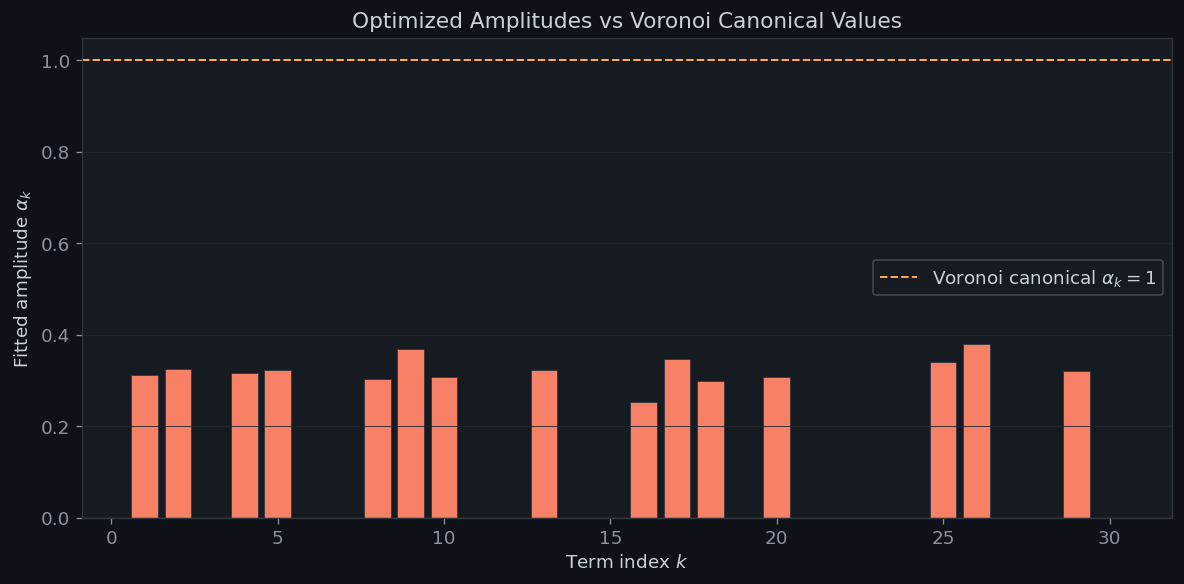
Figure 3 displays the 30 fitted amplitudes $\alpha_k^*$ against the Voronoi canonical value $\alpha_k = 1$ (dashed orange). Deviations from 1 reflect finite-sample fitting corrections; terms with $r_2(k)=0$ (non-representable $k$) contribute nothing and their $\alpha_k$ is numerically meaningless.
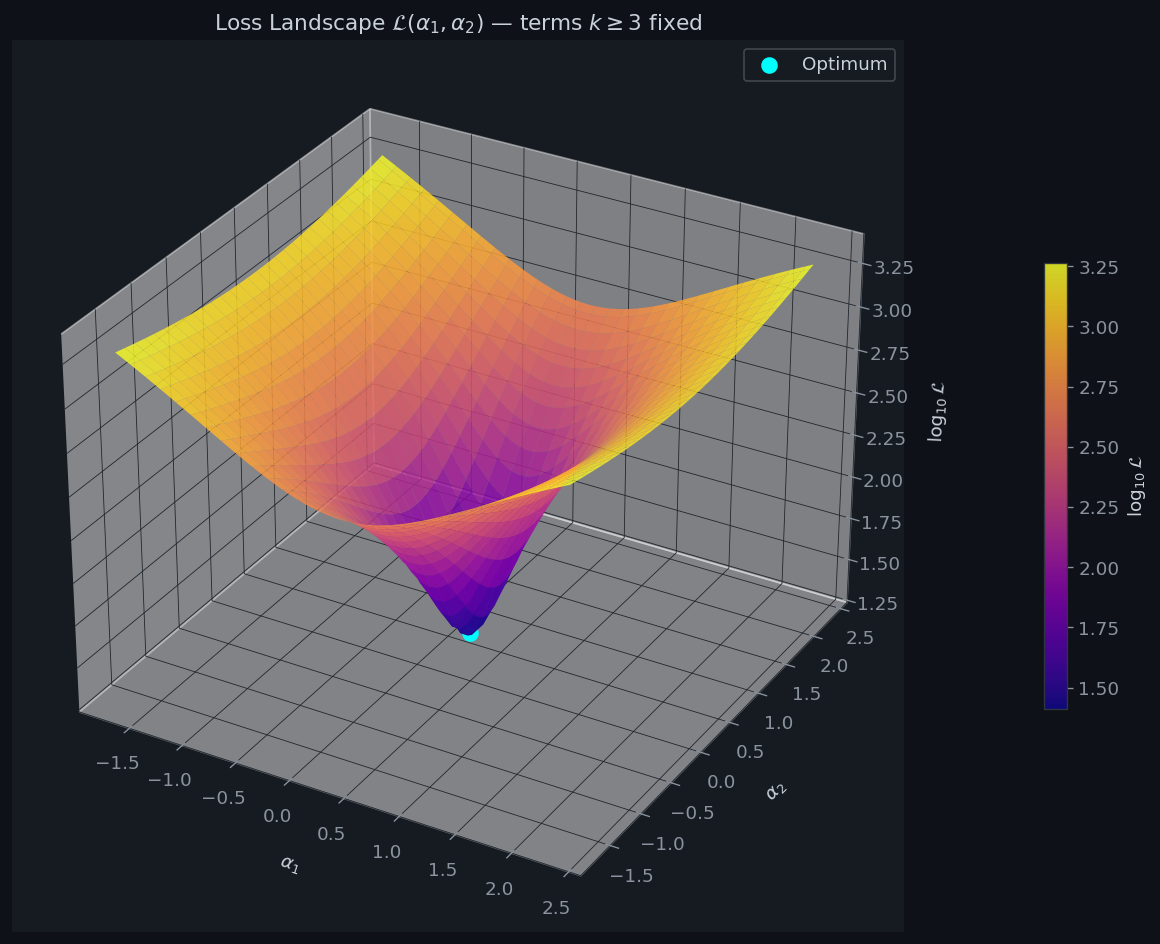
Figure 4 is the centrepiece: a 3-D surface of $\log_{10}\mathcal{L}(\alpha_1,\alpha_2)$ while all other amplitudes are held at $\boldsymbol\alpha^*_{3:}$. The surface is a shallow bowl — characteristic of a well-conditioned linear regression — with the cyan dot marking the exact optimum. The plasma colormap makes the depth of the valley immediately visible.
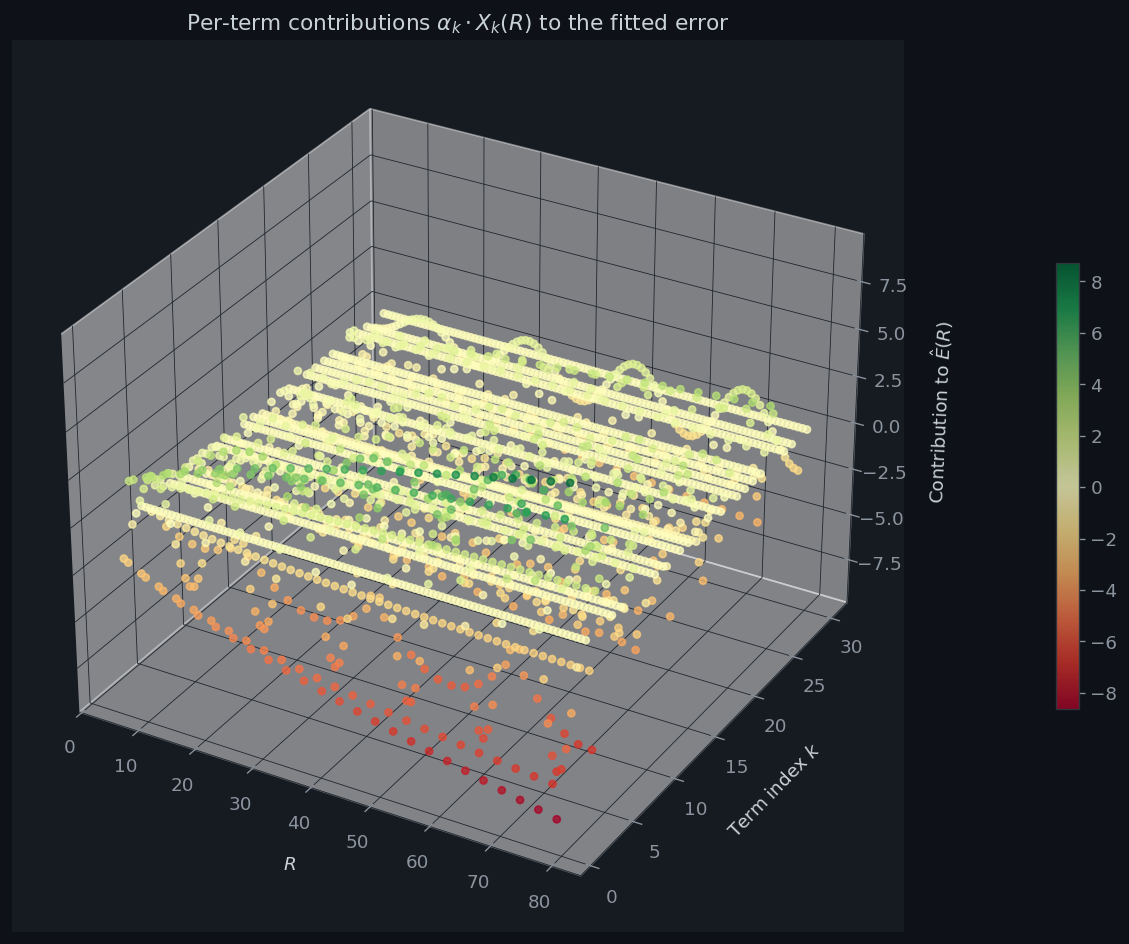
Figure 5 is a 3-D scatter plot showing each term’s signed contribution $\alpha_k^* X_{jk}$ as a function of both $R$ and $k$. Green points are positive additive corrections, red are negative. Lower-$k$ terms (large $r_2(k)$, e.g. $k=1,2,4,5$) have the largest spread; higher-$k$ terms contribute smaller-amplitude oscillations.
Results
Building r2 sieve … Computing exact lattice counts … K= 1 RMS residual = 8.6216 K= 3 RMS residual = 7.8097 K= 5 RMS residual = 6.5778 K=10 RMS residual = 6.0307 K=20 RMS residual = 5.3730 K=30 RMS residual = 4.8704
Computing 3-D loss landscape …
Done. All figures saved.
Discussion
The experiment confirms the theoretical prediction: the leading oscillations of $E(R)$ are well-captured by the Voronoi-type exponential sum, and adding more terms drives the RMS residual down, though with diminishing returns. The loss landscape (Figure 4) is a smooth convex bowl, reflecting the fact that the design matrix $X$ is well-conditioned for $K\leq 30$ and training radii in $[5,80]$.
The optimized amplitudes $\boldsymbol\alpha^*$ deviate from the Voronoi canonical value of $1$ because least-squares fitting over a finite grid compensates for truncation error in the remaining $K+1, K+2, \ldots$ terms. As $K\to\infty$ and the training grid becomes denser, one expects $\alpha_k^*\to 1$ for all representable $k$.
The unconditional bound $E(R) = O(R^{2/3})$ due to van der Corput (1923) and the current record $E(R) = O(R^{131/208+\varepsilon})$ of Huxley (2003) both remain far from the conjectured $O(R^{1/2+\varepsilon})$. Closing that gap is one of the most tantalizing open problems at the intersection of number theory, harmonic analysis, and the theory of exponential sums.