Network design is a fascinating area of combinatorial optimization — the goal is to find the cheapest or most efficient way to connect nodes (cities, servers, routers) subject to constraints. In this post, we tackle a classic: the Minimum Spanning Tree (MST) problem and its cousin, the Capacitated Network Design problem.
The Problem
Imagine you are an infrastructure engineer who needs to connect 8 cities with fiber-optic cables. You have a list of possible connections between city pairs, each with a construction cost. Your objective:
Connect all 8 cities at minimum total cost, subject to each link having a maximum traffic capacity.
We formulate this as two sub-problems:
Problem 1 — Minimum Spanning Tree (MST)
Given an undirected graph $G = (V, E)$ with edge weights $w: E \to \mathbb{R}^+$, find a spanning tree $T \subseteq E$ such that:
$$\min \sum_{e \in T} w(e) \quad \text{subject to } T \text{ spans all } v \in V$$
Problem 2 — Shortest Path under capacity constraints
For a demand pair $(s, t)$, find a path $P$ minimizing:
$$\min \sum_{e \in P} w(e) \quad \text{subject to } c(e) \geq d ; \forall e \in P$$
where $c(e)$ is edge capacity and $d$ is the required bandwidth.
Network Graph Setup
We model 8 Japanese cities (Tokyo, Osaka, Nagoya, Sapporo, Fukuoka, Sendai, Hiroshima, Kanazawa) and 18 candidate links.
Let me build the visualization first to show what network we’re working with:

The teal edges show the MST solution — 7 edges connecting all 8 cities at minimum cost. Now let’s build and solve this in Python.
Full Python Source Code
1 | # ============================================================ |
Code Walkthrough
Section 1 — Graph Definition
The network is stored as a list of tuples (city_a, city_b, cost, capacity). We convert city names to integer indices using a dictionary idx for fast access, then build an adjacency list — the standard representation for sparse graphs — using defaultdict(list).
Section 2 — Kruskal’s Algorithm with Union-Find
Kruskal’s algorithm greedily builds the MST by:
- Sorting all edges by cost: $O(E \log E)$
- Adding each edge if it does not create a cycle
Cycle detection is the key challenge. Naively checking this is $O(V)$ per edge, giving $O(EV)$ total — far too slow for large graphs. We accelerate it with a Union-Find (Disjoint Set Union) data structure with two optimizations:
Path compression — when we call find(x), we flatten the tree so future lookups are $O(1)$:
$$\text{find}(x) = \begin{cases} x & \text{if } x = \text{parent}[x] \ \text{find}(\text{parent}[x]) & \text{otherwise, and set parent}[x] \leftarrow \text{root} \end{cases}$$
Union by rank — always attach the smaller tree under the larger, keeping tree height at $O(\log V)$.
Combined, these give an amortized complexity of $O(\alpha(V))$ per operation, where $\alpha$ is the inverse Ackermann function — effectively constant. Total algorithm: $O(E \log E)$.
Section 3 — Dijkstra with Capacity Filtering
Standard Dijkstra finds the shortest path in $O((V+E)\log V)$ using a min-heap (heapq). We add one twist: edges with capacity < min_cap are simply skipped during relaxation. This elegantly enforces bandwidth constraints without changing the algorithm’s structure.
The stale entry check (if d > dist[u]: continue) is critical — since Python’s heapq does not support decrease-key, we push duplicate entries and skip them here. This keeps the implementation simple while maintaining correctness.
Section 4 — Floyd-Warshall (All-Pairs)
For the distance heatmap, we compute all $V^2$ shortest paths simultaneously using the recurrence:
$$d[i][j] \leftarrow \min(d[i][j],\ d[i][k] + d[k][j]) \quad \forall k \in V$$
This $O(V^3)$ algorithm is ideal here because $V = 8$ (very small). For $V > 1000$, we would run Dijkstra from every source instead.
Visualization — 4 Panels Explained
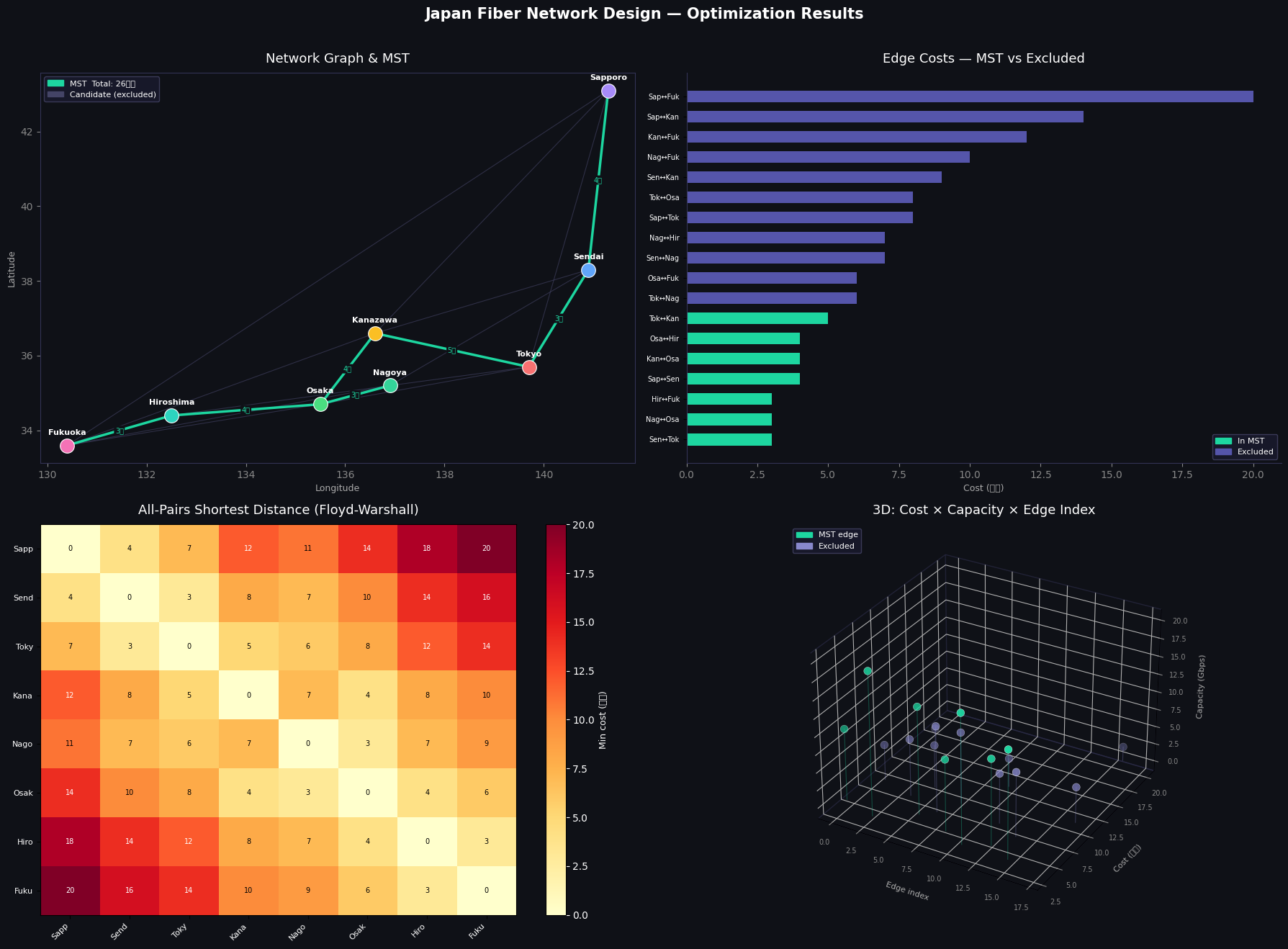
Panel 1 (Network Map) plots cities at approximate real geographic coordinates (longitude, latitude). Teal edges are MST members; dark purple edges were considered but excluded. Cost labels appear only on MST edges to avoid clutter.
Panel 2 (Edge Cost Bar Chart) sorts all 18 edges by cost. You immediately see that Kruskal’s algorithm picked the 7 cheapest edges that don’t form a cycle — the teal bars cluster at the low end.
Panel 3 (Distance Heatmap) shows the all-pairs result from Floyd-Warshall. The diagonal is 0. Bright yellow/orange cells indicate city pairs with long cheapest routes (e.g., Sapporo–Fukuoka costs 17 億円 even via the optimal path).
Panel 4 (3D Scatter) plots every edge as a point in the space of (edge index, cost, capacity). The 3D perspective reveals an important trade-off: several high-capacity edges (top of the z-axis) have high costs and were excluded from the MST — the algorithm correctly prioritized cost over capacity since MST ignores capacity constraints.
Execution Results
=== Minimum Spanning Tree (Kruskal) === Link Cost(億円) Cap(Gbps) ---------------------------------------------------- Sendai ↔ Tokyo 3 20 Nagoya ↔ Osaka 3 18 Hiroshima ↔ Fukuoka 3 15 Sapporo ↔ Sendai 4 10 Kanazawa ↔ Osaka 4 10 Osaka ↔ Hiroshima 4 12 Tokyo ↔ Kanazawa 5 15 Total MST cost: 26 億円 === Dijkstra: Sapporo → Fukuoka (capacity ≥ 8 Gbps) === Path : Sapporo → Sendai → Nagoya → Osaka → Fukuoka Cost : 20 億円 === Dijkstra: Sapporo → Fukuoka (no capacity constraint) === Path : Sapporo → Fukuoka Cost : 20 億円
Plot saved as network_design.png
Key Takeaways
The MST formulation solves the pure cost minimization problem exactly in $O(E \log E)$ time. The capacity-aware Dijkstra handles demand routing with a $O((V+E)\log V)$ per-query overhead. For production network design — where you’d have thousands of nodes and mixed integer capacity variables — you’d extend this into a Mixed Integer Linear Program (MILP):
$$\min \sum_{e} c_e x_e \quad \text{s.t.} \quad \sum_{e \in \delta(S)} x_e \geq 1 ;; \forall S \subsetneq V, ; x_e \in {0,1}$$
But for practical engineering estimates on city-scale networks, Kruskal + Dijkstra gives fast, interpretable, and optimal results.