1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
| import numpy as np
import matplotlib.pyplot as plt
from scipy.optimize import minimize, fsolve
import seaborn as sns
from mpl_toolkits.mplot3d import Axes3D
import pandas as pd
class MultilateralDiplomacy:
"""
A class to model and optimize multilateral diplomatic strategies
using game-theoretic principles.
"""
def __init__(self, countries, alpha, beta, gamma):
"""
Initialize the diplomatic game.
Parameters:
- countries: list of country names
- alpha: array of benefit coefficients from others' cooperation
- beta: array of cost coefficients of own cooperation
- gamma: array of synergy coefficients
"""
self.countries = countries
self.n_countries = len(countries)
self.alpha = np.array(alpha)
self.beta = np.array(beta)
self.gamma = np.array(gamma)
def payoff(self, x, country_idx):
"""
Calculate payoff for a specific country given all cooperation levels.
Payoff function: U_i = α_i * Σ(x_j) - β_i * x_i^2 + γ_i * x_i * Σ(x_j)
where j ≠ i
"""
others_cooperation = np.sum(x) - x[country_idx]
own_cooperation = x[country_idx]
payoff = (self.alpha[country_idx] * others_cooperation -
self.beta[country_idx] * own_cooperation**2 +
self.gamma[country_idx] * own_cooperation * others_cooperation)
return payoff
def best_response(self, x, country_idx):
"""
Calculate best response for country i given others' strategies.
Taking derivative of payoff w.r.t. x_i and setting to zero:
dU_i/dx_i = -2β_i * x_i + γ_i * Σ(x_j) = 0
Optimal x_i = γ_i * Σ(x_j) / (2β_i)
"""
others_cooperation = np.sum(x) - x[country_idx]
if self.beta[country_idx] == 0:
return 1.0
optimal_x = (self.gamma[country_idx] * others_cooperation) / (2 * self.beta[country_idx])
return np.clip(optimal_x, 0, 1)
def nash_equilibrium_system(self, x):
"""
System of equations for Nash equilibrium.
Each country plays their best response given others' strategies.
"""
equations = []
for i in range(self.n_countries):
best_resp = self.best_response(x, i)
equations.append(x[i] - best_resp)
return equations
def find_nash_equilibrium(self, initial_guess=None):
"""
Find Nash equilibrium using iterative best response method.
"""
if initial_guess is None:
x = np.random.rand(self.n_countries) * 0.5
else:
x = np.array(initial_guess)
equilibrium = fsolve(self.nash_equilibrium_system, x)
equilibrium = np.clip(equilibrium, 0, 1)
return equilibrium
def social_welfare_optimization(self):
"""
Find socially optimal solution by maximizing total welfare.
Social welfare = Σ U_i(x)
"""
def negative_social_welfare(x):
total_welfare = sum(self.payoff(x, i) for i in range(self.n_countries))
return -total_welfare
constraints = [{'type': 'ineq', 'fun': lambda x: x},
{'type': 'ineq', 'fun': lambda x: 1 - x}]
x0 = np.ones(self.n_countries) * 0.5
result = minimize(negative_social_welfare, x0, method='SLSQP',
constraints=constraints)
return result.x if result.success else None
def analyze_stability(self, equilibrium):
"""
Analyze the stability of the equilibrium by computing payoff changes
from unilateral deviations.
"""
stability_analysis = {}
for i, country in enumerate(self.countries):
current_payoff = self.payoff(equilibrium, i)
deviations = np.linspace(0, 1, 21)
deviation_payoffs = []
for dev in deviations:
x_dev = equilibrium.copy()
x_dev[i] = dev
deviation_payoffs.append(self.payoff(x_dev, i))
stability_analysis[country] = {
'current_payoff': current_payoff,
'deviations': deviations,
'deviation_payoffs': deviation_payoffs,
'is_stable': all(p <= current_payoff + 1e-6 for p in deviation_payoffs)
}
return stability_analysis
countries = ['USA', 'EU', 'China', 'Japan']
alpha = [0.8, 0.9, 0.7, 0.85]
beta = [0.6, 0.4, 0.8, 0.5]
gamma = [0.3, 0.4, 0.2, 0.35]
game = MultilateralDiplomacy(countries, alpha, beta, gamma)
print("=== Multilateral Trade Agreement Negotiation Analysis ===\n")
nash_eq = game.find_nash_equilibrium()
print("Nash Equilibrium Cooperation Levels:")
for i, country in enumerate(countries):
print(f"{country}: {nash_eq[i]:.3f}")
print(f"\nNash Equilibrium Payoffs:")
nash_payoffs = [game.payoff(nash_eq, i) for i in range(len(countries))]
for i, country in enumerate(countries):
print(f"{country}: {nash_payoffs[i]:.3f}")
social_opt = game.social_welfare_optimization()
print(f"\nSocial Optimum Cooperation Levels:")
for i, country in enumerate(countries):
print(f"{country}: {social_opt[i]:.3f}")
print(f"\nSocial Optimum Payoffs:")
social_payoffs = [game.payoff(social_opt, i) for i in range(len(countries))]
for i, country in enumerate(countries):
print(f"{country}: {social_payoffs[i]:.3f}")
nash_total_welfare = sum(nash_payoffs)
social_total_welfare = sum(social_payoffs)
welfare_gap = social_total_welfare - nash_total_welfare
print(f"\nWelfare Analysis:")
print(f"Nash Equilibrium Total Welfare: {nash_total_welfare:.3f}")
print(f"Social Optimum Total Welfare: {social_total_welfare:.3f}")
print(f"Welfare Gap (Price of Anarchy): {welfare_gap:.3f}")
print(f"Efficiency Loss: {(welfare_gap/social_total_welfare)*100:.2f}%")
stability = game.analyze_stability(nash_eq)
print(f"\nStability Analysis:")
for country, analysis in stability.items():
status = "Stable" if analysis['is_stable'] else "Unstable"
print(f"{country}: {status} (Current payoff: {analysis['current_payoff']:.3f})")
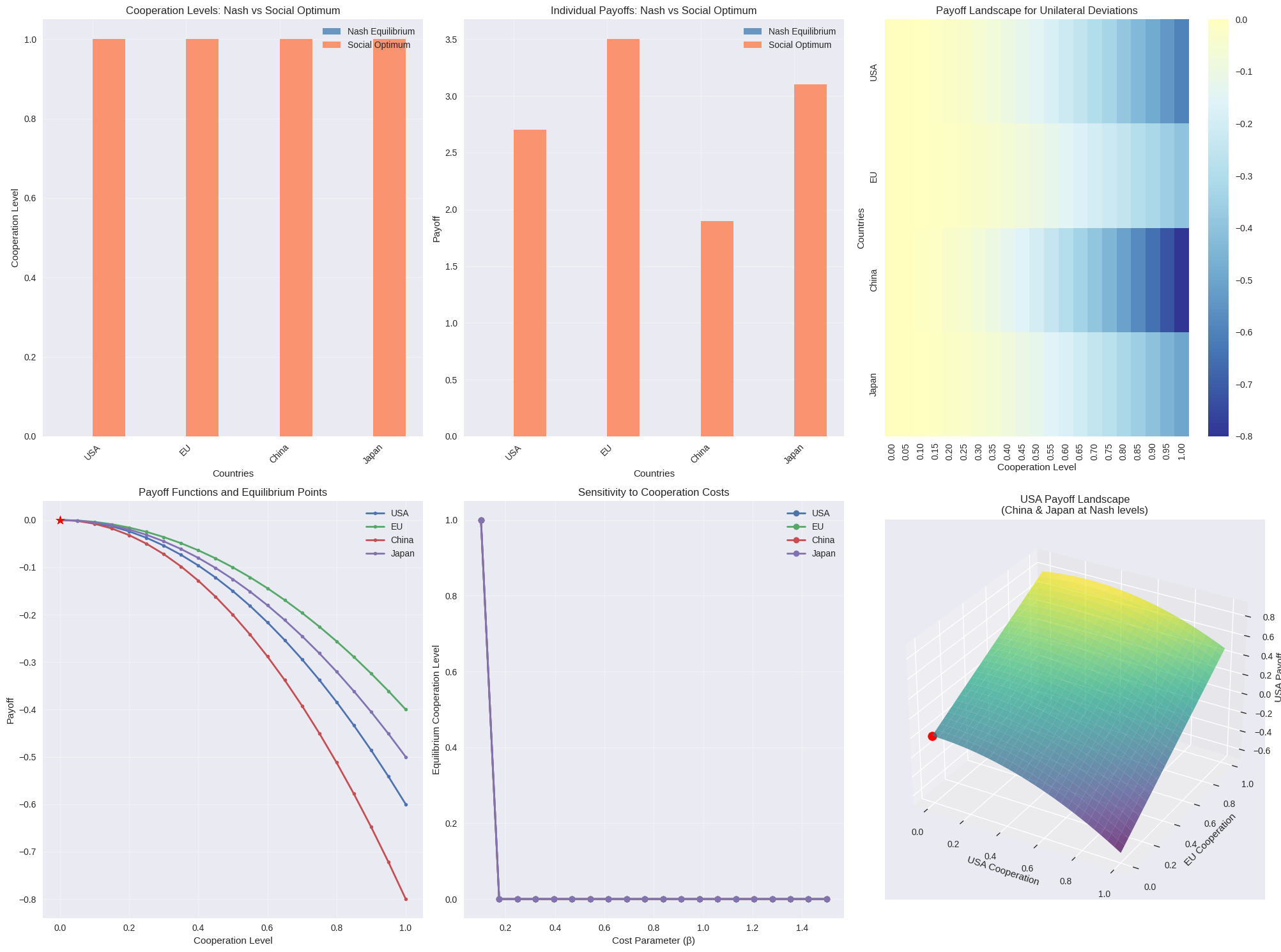
plt.style.use('seaborn-v0_8')
fig = plt.figure(figsize=(20, 15))
ax1 = plt.subplot(2, 3, 1)
x_pos = np.arange(len(countries))
width = 0.35
plt.bar(x_pos - width/2, nash_eq, width, label='Nash Equilibrium',
alpha=0.8, color='steelblue')
plt.bar(x_pos + width/2, social_opt, width, label='Social Optimum',
alpha=0.8, color='coral')
plt.xlabel('Countries')
plt.ylabel('Cooperation Level')
plt.title('Cooperation Levels: Nash vs Social Optimum')
plt.xticks(x_pos, countries, rotation=45)
plt.legend()
plt.grid(True, alpha=0.3)
ax2 = plt.subplot(2, 3, 2)
plt.bar(x_pos - width/2, nash_payoffs, width, label='Nash Equilibrium',
alpha=0.8, color='steelblue')
plt.bar(x_pos + width/2, social_payoffs, width, label='Social Optimum',
alpha=0.8, color='coral')
plt.xlabel('Countries')
plt.ylabel('Payoff')
plt.title('Individual Payoffs: Nash vs Social Optimum')
plt.xticks(x_pos, countries, rotation=45)
plt.legend()
plt.grid(True, alpha=0.3)
ax3 = plt.subplot(2, 3, 3)
stability_data = []
for country in countries:
stability_data.append(stability[country]['deviation_payoffs'])
stability_df = pd.DataFrame(stability_data,
columns=[f'{d:.2f}' for d in stability[countries[0]]['deviations']],
index=countries)
sns.heatmap(stability_df, annot=False, cmap='RdYlBu_r', center=0, ax=ax3)
plt.title('Payoff Landscape for Unilateral Deviations')
plt.xlabel('Cooperation Level')
plt.ylabel('Countries')
ax4 = plt.subplot(2, 3, 4)
for i, country in enumerate(countries):
analysis = stability[country]
plt.plot(analysis['deviations'], analysis['deviation_payoffs'],
label=country, marker='o', linewidth=2, markersize=4)
current_coop = nash_eq[i]
current_payoff = analysis['current_payoff']
plt.scatter([current_coop], [current_payoff],
s=100, marker='*', color='red', zorder=5)
plt.xlabel('Cooperation Level')
plt.ylabel('Payoff')
plt.title('Payoff Functions and Equilibrium Points')
plt.legend()
plt.grid(True, alpha=0.3)
ax5 = plt.subplot(2, 3, 5)
beta_range = np.linspace(0.1, 1.5, 20)
equilibrium_paths = {country: [] for country in countries}
for beta_val in beta_range:
temp_beta = [beta_val] * len(countries)
temp_game = MultilateralDiplomacy(countries, alpha, temp_beta, gamma)
temp_eq = temp_game.find_nash_equilibrium()
for i, country in enumerate(countries):
equilibrium_paths[country].append(temp_eq[i])
for country in countries:
plt.plot(beta_range, equilibrium_paths[country],
label=country, marker='o', linewidth=2)
plt.xlabel('Cost Parameter (β)')
plt.ylabel('Equilibrium Cooperation Level')
plt.title('Sensitivity to Cooperation Costs')
plt.legend()
plt.grid(True, alpha=0.3)
ax6 = plt.subplot(2, 3, 6, projection='3d')
x1_range = np.linspace(0, 1, 30)
x2_range = np.linspace(0, 1, 30)
X1, X2 = np.meshgrid(x1_range, x2_range)
Z = np.zeros_like(X1)
for i in range(len(x1_range)):
for j in range(len(x2_range)):
x_temp = np.array([X1[i,j], X2[i,j], nash_eq[2], nash_eq[3]])
Z[i,j] = game.payoff(x_temp, 0)
surface = ax6.plot_surface(X1, X2, Z, cmap='viridis', alpha=0.7)
ax6.scatter([nash_eq[0]], [nash_eq[1]], [nash_payoffs[0]],
color='red', s=100, label='Nash Equilibrium')
ax6.set_xlabel('USA Cooperation')
ax6.set_ylabel('EU Cooperation')
ax6.set_zlabel('USA Payoff')
ax6.set_title('USA Payoff Landscape\n(China & Japan at Nash levels)')
plt.tight_layout()
plt.show()
print("\n=== Coalition Analysis ===")
coalitions = [('USA', 'EU'), ('USA', 'China'), ('USA', 'Japan'),
('EU', 'China'), ('EU', 'Japan'), ('China', 'Japan')]
coalition_benefits = {}
for coalition in coalitions:
idx1, idx2 = countries.index(coalition[0]), countries.index(coalition[1])
def coalition_welfare(x):
x_full = nash_eq.copy()
x_full[idx1], x_full[idx2] = x[0], x[1]
return -(game.payoff(x_full, idx1) + game.payoff(x_full, idx2))
from scipy.optimize import minimize
result = minimize(coalition_welfare, [nash_eq[idx1], nash_eq[idx2]],
bounds=[(0, 1), (0, 1)])
if result.success:
optimal_coop = result.x
x_coalition = nash_eq.copy()
x_coalition[idx1], x_coalition[idx2] = optimal_coop[0], optimal_coop[1]
coalition_payoff1 = game.payoff(x_coalition, idx1)
coalition_payoff2 = game.payoff(x_coalition, idx2)
benefit1 = coalition_payoff1 - nash_payoffs[idx1]
benefit2 = coalition_payoff2 - nash_payoffs[idx2]
coalition_benefits[coalition] = {
'cooperation': optimal_coop,
'benefits': (benefit1, benefit2),
'total_benefit': benefit1 + benefit2
}
print("\nPotential Coalition Benefits:")
for coalition, data in sorted(coalition_benefits.items(),
key=lambda x: x[1]['total_benefit'], reverse=True):
print(f"{coalition[0]}-{coalition[1]}: "
f"Benefits = ({data['benefits'][0]:.3f}, {data['benefits'][1]:.3f}), "
f"Total = {data['total_benefit']:.3f}")
|