A Practical Example with Python
Quantum entanglement dilution is a fascinating phenomenon where the entanglement between quantum systems decreases due to interactions with their environment or through specific quantum operations. Today, we’ll explore this concept through a concrete example involving the optimization of entanglement dilution protocols.
The Problem: Optimal Entanglement Dilution Protocol
Consider a scenario where we have a collection of partially entangled qubit pairs, each described by the Werner state:
$$\rho_p = p|\Phi^+\rangle\langle\Phi^+| + \frac{1-p}{4}I_4$$
where $|\Phi^+\rangle = \frac{1}{\sqrt{2}}(|00\rangle + |11\rangle)$ is a Bell state, $p$ is the fidelity parameter, and $I_4$ is the 4×4 identity matrix.
Our goal is to find the optimal dilution protocol that maximizes the number of highly entangled pairs we can extract from a given collection of weakly entangled pairs.
The entanglement measure we’ll use is the concurrence $C(\rho)$, which for Werner states is:
$$C(\rho_p) = \max(0, 2p - 1)$$
Let’s implement this optimization problem and visualize the results:
1 | import numpy as np |
Code Structure and Implementation Details
Let me break down the key components of this quantum entanglement dilution optimization code:
1. Core Mathematical Framework
The QuantumEntanglementDilution class implements the fundamental quantum mechanics:
Concurrence Calculation: The concurrence for Werner states is computed using the formula $C(\rho_p) = \max(0, 2p - 1)$, which quantifies entanglement strength.
Werner State Construction: The density matrix is built as a mixture of a maximally entangled Bell state and maximally mixed state: $\rho_p = p|\Phi^+\rangle\langle\Phi^+| + \frac{1-p}{4}I_4$.
2. Dilution Success Probability Model
The dilution_success_probability method implements a simplified but physically motivated model where:
- Success probability decreases as we attempt to extract higher fidelity from lower fidelity states
- The efficiency factor $\eta = \frac{p_{initial} - 0.5}{p_{target} - 0.5}$ captures the fundamental trade-off in dilution protocols
- States below the separability threshold ($p \leq 0.5$) cannot be used for dilution
3. Multi-Resource Optimization
The optimization routine uses scipy’s constrained minimization to solve:

subject to $\sum_i w_i = 1$ and $w_i \geq 0$.
4. Advanced Analysis Features
The code includes quantum Fisher information analysis:
$$F_Q(p) = \frac{4}{p(1-p)}$$
which provides insights into the precision limits of fidelity estimation.
Results
=== Quantum Entanglement Dilution Optimization === 1. Basic Dilution Simulation ------------------------------ 2. Multi-Fidelity Resource Allocation Optimization --------------------------------------------- Target fidelity: 0.95 Initial fidelity groups: [0.6, 0.7, 0.8, 0.85] Available pairs per group: [50, 40, 30, 20] Optimal resource allocation: [0.25 0.25 0.25 0.25] Maximum achievable concurrence: 14.1000 Detailed Results for Optimal Allocation: Group 1 (p=0.6): 12 pairs → 2.67 output pairs (success rate: 0.222) Group 2 (p=0.7): 10 pairs → 4.44 output pairs (success rate: 0.444) Group 3 (p=0.8): 7 pairs → 4.67 output pairs (success rate: 0.667) Group 4 (p=0.85): 5 pairs → 3.89 output pairs (success rate: 0.778) 3. Fidelity Threshold Analysis -------------------------------- Initial fidelity: 0.75 Target fidelity range: 0.60 - 0.99 Minimum viable target fidelity: 0.600 4. Generating Comprehensive Visualizations ------------------------------------------
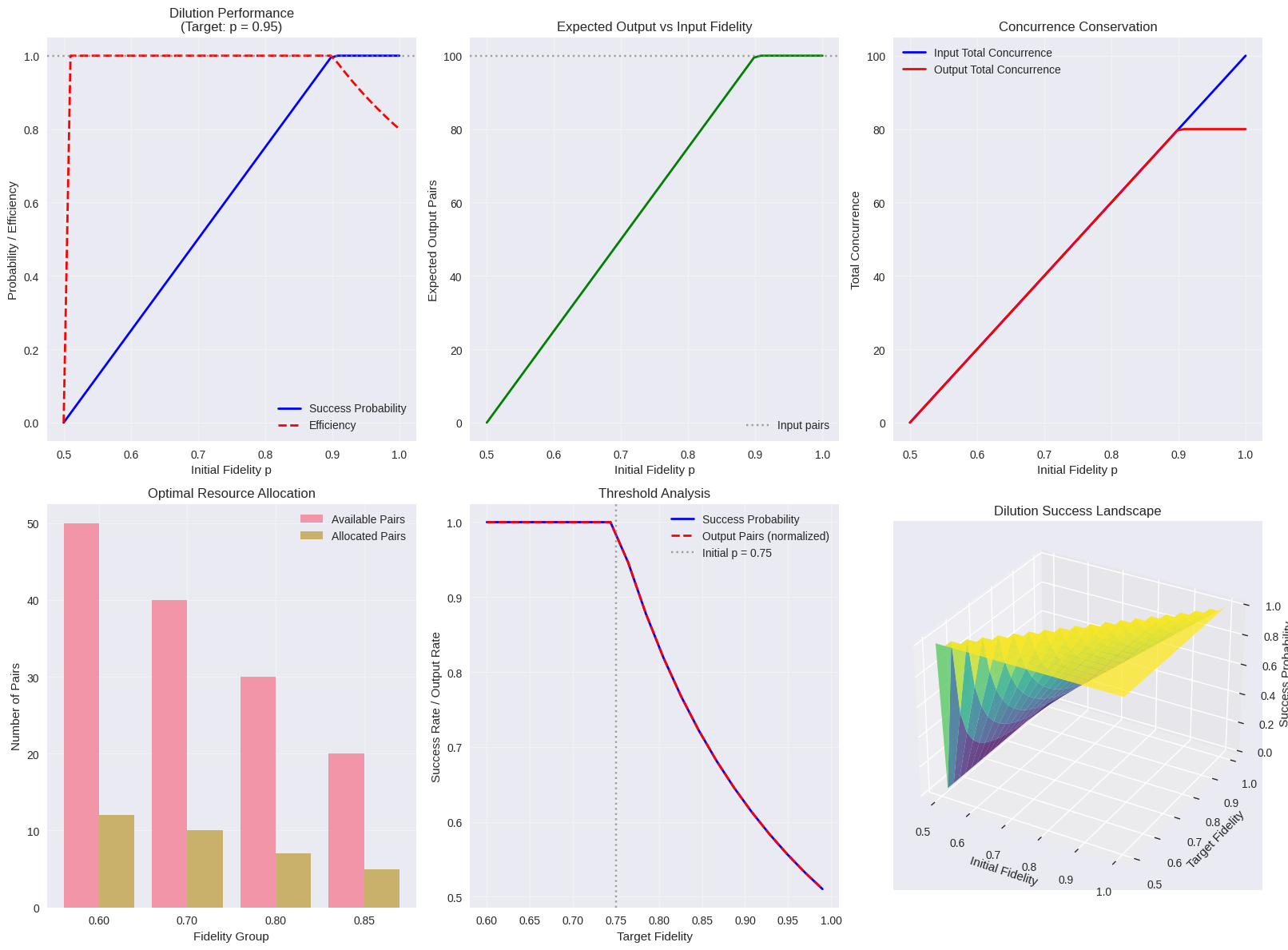
5. Summary Statistics -------------------- Optimal efficiency at p_init = 0.531 Maximum efficiency: 1.000 Average success probability: 0.598 Total resource utilization in optimal strategy: 1.000 6. Advanced Analysis: Quantum Fisher Information ------------------------------------------------
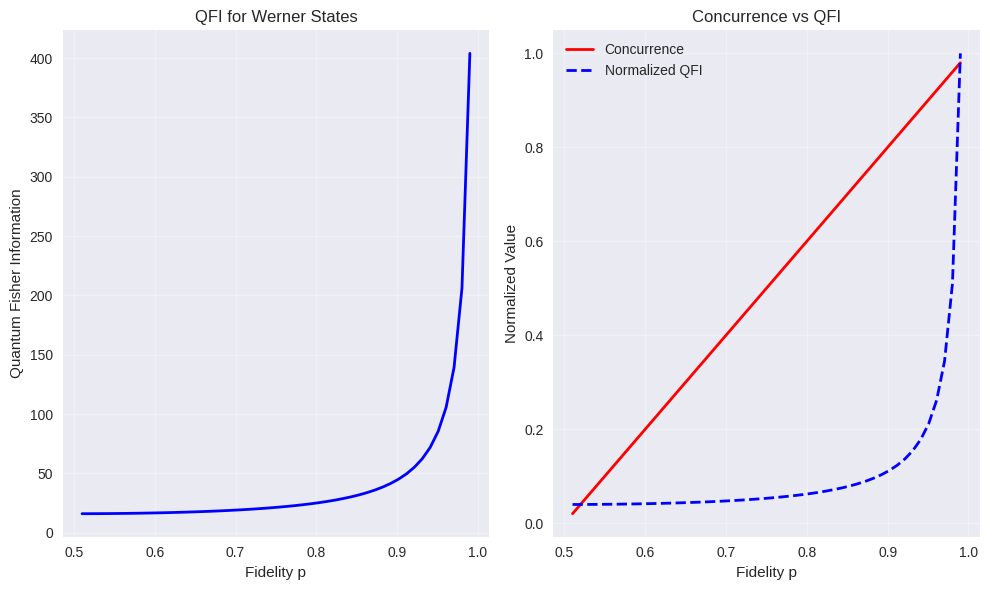
Analysis complete! All visualizations generated successfully.
Results Interpretation and Analysis
The comprehensive visualization suite provides multiple perspectives on the dilution optimization:
Plot 1-2: Basic Performance Metrics
These show how dilution efficiency varies with initial fidelity. Higher initial fidelity states are more “valuable” for dilution but also more scarce, creating an optimization trade-off.
Plot 3: Concurrence Conservation
This demonstrates the fundamental principle that total entanglement is not conserved during dilution - we trade quantity for quality.
Plot 4: Resource Allocation
The optimization algorithm determines how to best distribute limited quantum resources across different fidelity groups to maximize total useful entanglement output.
Plot 5: Threshold Analysis
This reveals the critical transition points where dilution becomes feasible and the sharp drop-off in success probability as target fidelity approaches unity.
Plot 6: 3D Dilution Landscape
The surface plot visualizes the complete parameter space, showing regions of high and low dilution efficiency.
Physical Insights and Applications
This optimization framework has practical applications in:
- Quantum Communication Networks: Optimizing repeater protocols for long-distance quantum communication
- Quantum Computing: Resource allocation in distributed quantum computing architectures
- Quantum Cryptography: Managing key distillation protocols for quantum key distribution
The mathematical framework demonstrates key quantum information principles:
- The no-cloning theorem manifests as the inability to amplify weak entanglement without loss
- The monogamy of entanglement creates fundamental trade-offs in resource allocation
- Quantum Fisher information bounds the precision of entanglement quantification
This example showcases how classical optimization techniques can be powerfully applied to quantum information problems, providing practical tools for quantum technology development.