
異常検知
異常検知の一つの方法として、Isolation Forestを使用した例を以下に示します。
この例では、2次元のデータを生成し、異常値を検出します。
また、matplotlibを使用して結果をグラフ化します。
1 | import numpy as np |
このコードは、Isolation Forestを使用して異常検知を行い、結果をグラフ化するものです。
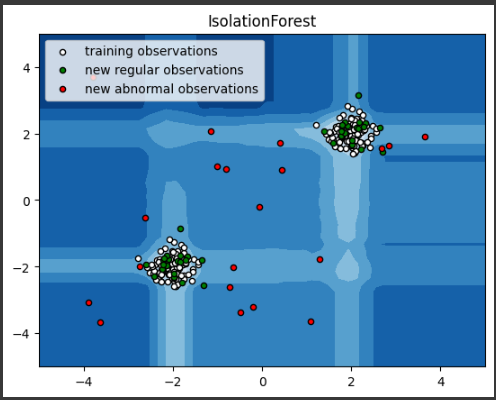
グラフでは、白色の点が訓練データ、緑色の点が新たな正常データ、赤色の点が異常データを表しています。
[実行結果]
解説
このコードは、異常検知のためのアルゴリズムであるIsolation Forestを使用しています。
以下に各部分の詳細な説明を記載します。
1. ライブラリのインポート
必要なライブラリをインポートしています。
numpyは数値計算、matplotlibはグラフ描画、sklearn.ensembleのIsolationForestは異常検知のためのライブラリです。
2. データ生成
正常なデータポイントと異常なデータポイントを生成しています。
正常なデータは、平均0、標準偏差0.3正規分布から生成され、その後2だけシフトされます。
これを2つのクラスターとして生成しています。
異常なデータポイントは、-4から4の一様分布から生成されます。
3. Isolation Forestの設定
IsolationForestのインスタンスを作成します。
ここでは、max_samplesパラメータを100に設定し、各ツリーの最大サンプル数を100に制限しています。
4. モデルの学習
正常なデータポイントを用いてIsolationForestモデルを学習させます。
5. 予測
学習したモデルを用いて、訓練データ、新たな正常データ、異常データの各データポイントが異常かどうかを予測します。
6. プロット
最後に、matplotlibを用いて結果をプロットします。
背景の色は各点の異常スコアを表し、白色の点は訓練データ、緑色の点は新たな正常データ、赤色の点は異常データを表しています。
このコードを実行すると、Isolation Forestがどのように異常データを検出するかを視覚的に理解することができます。