前回は、質疑応答のためのデータセットの準備と必要なライブラリのインストールを行いました。
今回は、わかち書きとファインチューニングを行います。
わかち書き
日本語はわかち書きに変換すると精度が上がります。
下記のコードでわかち書きを行います。
[Google Colaboratory]
1 | import json |
実行結果は以下の通りです。
[実行結果]
1 | Warning Remove Text: 冬 期間 |
実行結果として次の2ファイルが出力されます。
- wakati_DDQA-1.0_RC-QA_train.json
分かち書きした学習データ - wakati_DDQA-1.0_RC-QA_dev.json
分かち書きした検証データ
ファインチューニングの実行
質疑応答のファインチューニングを行います。
各パラメータの意味は次の通りです。
- model_type
モデル識別 - model_name_or_path
モデル名 - do_train
学習するかどうか - do_eval
検証するかどうか - max_seq_length
最大シーケンス長 - per_gpu_train_batch_size
バッチサイズ - learning_rate
学習率 - num_train_epochs
学習のエポック数 - train_file
学習データ(csvファイルまたはjsonファイル) - predict_file
検証データ(csvファイルまたはjsonファイル) - output_dir
出力先フォルダのパス - overwrite_output_dir
出力先フォルダの上書き
[Google Colaboratory]
1 | %%time |
[実行結果]
1 | 10/03/2021 00:15:58 - WARNING - __main__ - Process rank: -1, device: cuda, n_gpu: 1, distributed training: False, 16-bits training: False |
2時間7分ほどかかりました。(;^_^A
学習結果の確認
TensorBoardで学習結果を確認します。
[Google Colaboratory]
1 | # 学習状況の確認 |
[実行結果]
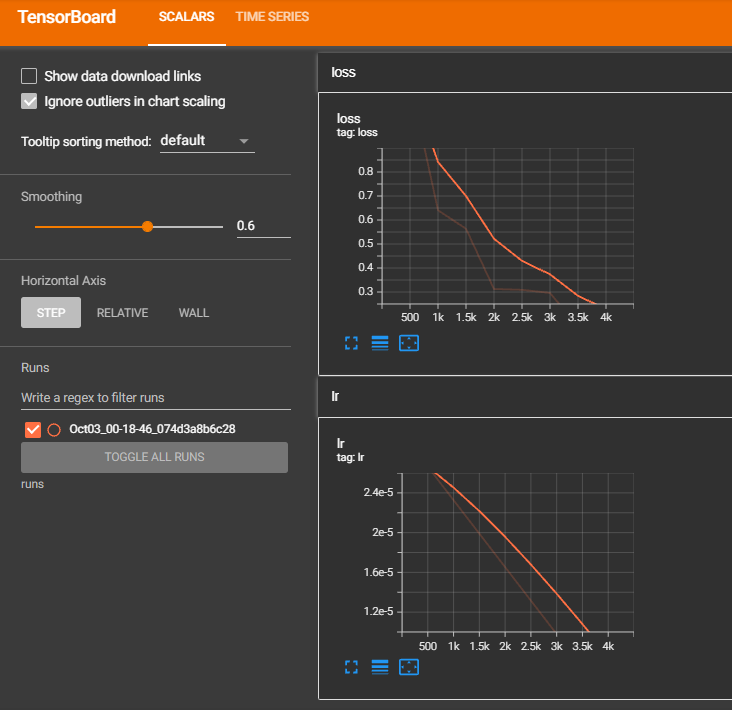
損失(Loss)が0に収束しているため、きちんと学習できていることが分かります。
次回は、学習したモデルを使って質疑応答を行います。