これまで学習アルゴリズムとしてPPO2を使っていましたが、今回からACKTRを使ってみます。
ACKTR は TPROとActor-Criticを組み合わせた学習法です。
- TPRO(Trust Region Policy Optimization)
高い報酬が得られる行動を優先し、低い報酬しか得られない行動を避けるように方策を最適化する学習アルゴリズム VPG(Vanilla Policy Gradient) を、学習が安定するように改良した学習法。 - Actor-Critic
「方策」と「価値関数」の両方を利用した学習法。
「方策」は行動選択に用いられるため Actor と呼ばれ、「価値関数」を予測する部分はActorが選択した行動を批判するため Critic と呼ばれています。
強化学習のパラメータ
強化学習時のパラメータと学習用・検証用データスパンは下記の通りです。
今回は学習データと検証データの期間を指定しています。さすがに同じ期間であればそれなりの結果になるかという狙いです。
学習アルゴリズム
ACKTR参照する直前データ数
50学習データ
[2017-07-14 ~ 2018-05-12] 1日足データ検証データ
[2017-07-14 ~ 2018-05-12] 1日足データ
ソース
ソースは下記の通りです。
[ソース]
1 | import os, gym |
simulation関数 の第2引数に 参照する直前データ数 を指定できるようにしています。
実行結果
実行結果は次のようになりました。
[コンソール出力]
1 | info: {'total_reward': 52039260000.0, 'total_profit': 14.47817840056156, 'position': 1} |
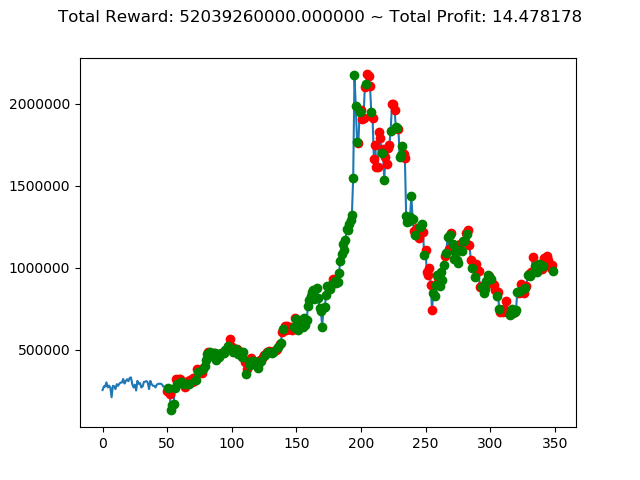
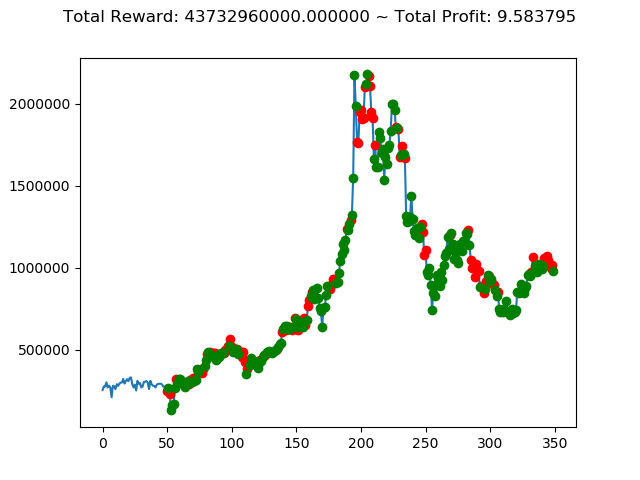
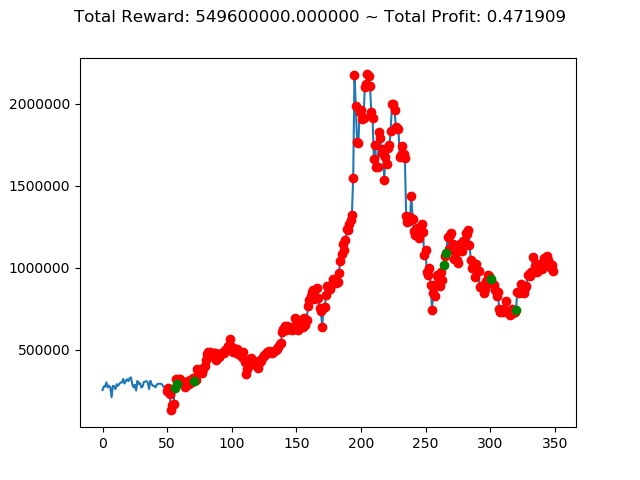
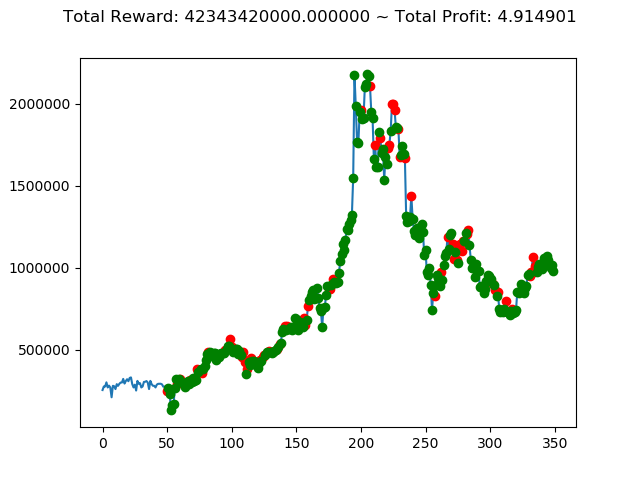
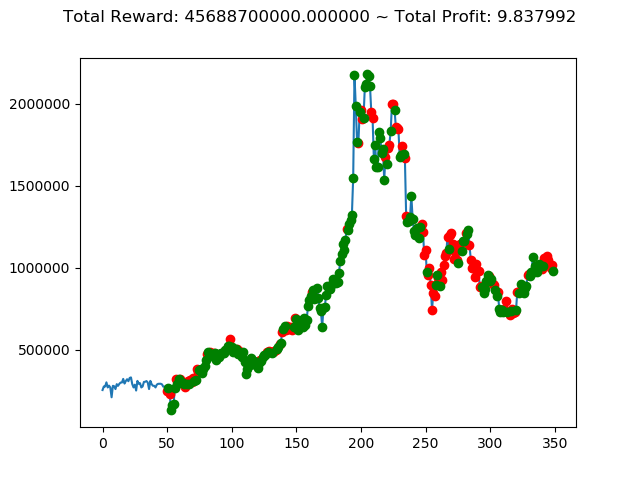
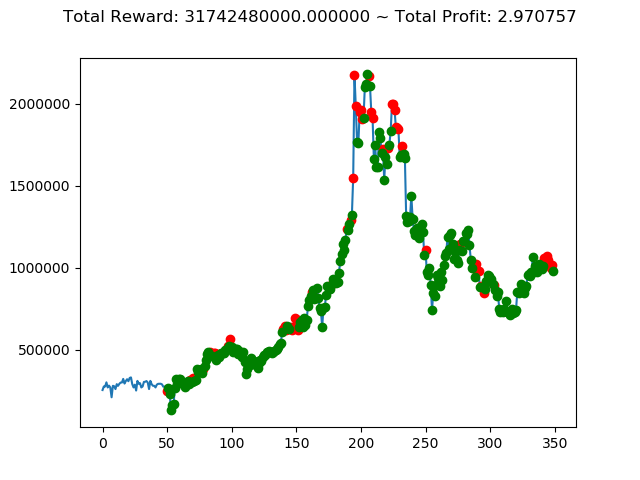
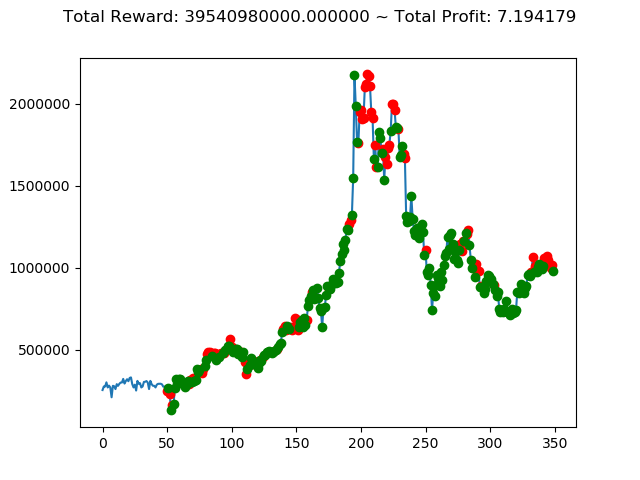
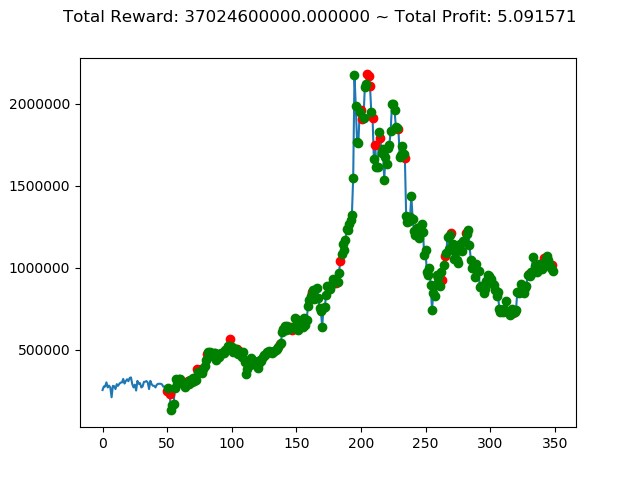
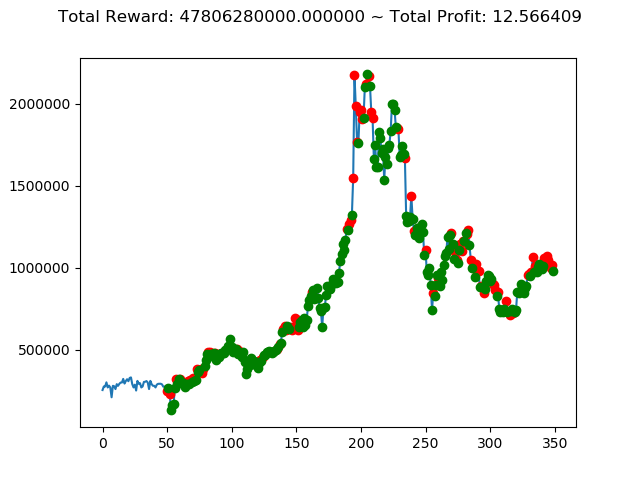
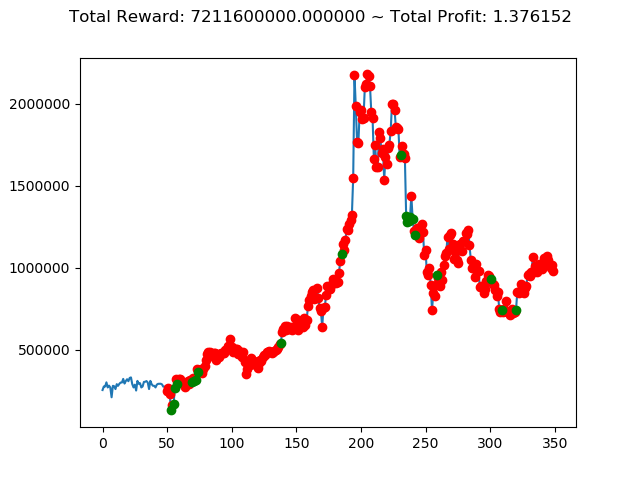
上記のトータル報酬を表にまとめてみます。
| No. | トータル報酬(今回) |
|---|---|
| ① | 52,039,260,000円 |
| ② | 43,732,960,000円 |
| ③ | 549,600,000円 |
| ④ | 42,343,420,000円 |
| ⑤ | 45,688,700,000円 |
| ⑥ | 31,742,480,000円 |
| ⑦ | 39,540,980,000円 |
| ⑧ | 37,024,600,000円 |
| ⑨ | 47,806,280,000円 |
| ⑩ | 7,211,600,000円 |
さすがに学習データと検証データ同じであれば、全勝できますね。
といいますか、これで負け越したら「なにを学習しているんだ??」ということになりますからね。
今後は今回学習したモデルをいろいろなパターンの検証データで投資成績を評価していきます。