パックマンを各学習アルゴリズムで攻略します。
今回使用する学習アルゴリズムは ACKTR です。
ACKTR は TPROとActor-Criticを組み合わせた学習法です。
- TPRO(Trust Region Policy Optimization)
高い報酬が得られる行動を優先し、低い報酬しか得られない行動を避けるように方策を最適化する学習アルゴリズム VPG(Vanilla Policy Gradient) を、学習が安定するように改良した学習法。 - Actor-Critic
「方策」と「価値関数」の両方を利用した学習法。
「方策」は行動選択に用いられるため Actor と呼ばれ、「価値関数」を予測する部分はActorが選択した行動を批判するため Critic と呼ばれています。
ACKTRでパックマンを攻略
学習アルゴリズム ACKTR の学習済みモデル(Stable Baselines Zoo提供)を使ってパックマンを実行し、その様子を動画ファイルに出力します。
各オプションは以下の通りです。
- 環境(env)
MsPacmanNoFrameskip-v4 - 学習アルゴリズム(algo)
ACKTR - ステップ数(n)
1000
[コマンド]
1 | python3.7 -m utils.record_video --algo acktr --env MsPacmanNoFrameskip-v4 -n 1000 |
実行結果は次の通りです。(Ubuntu 19.10で動作確認しています。)
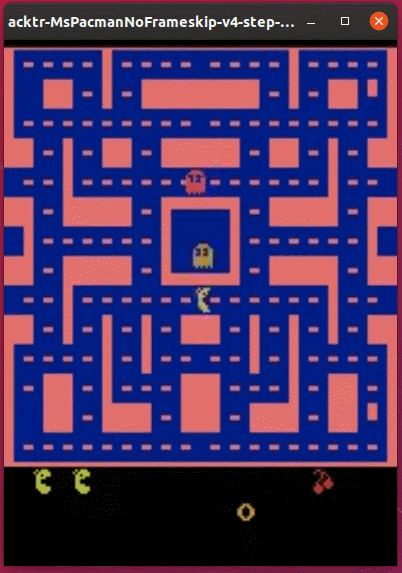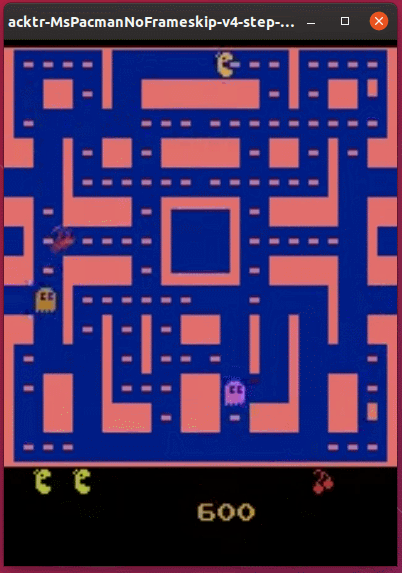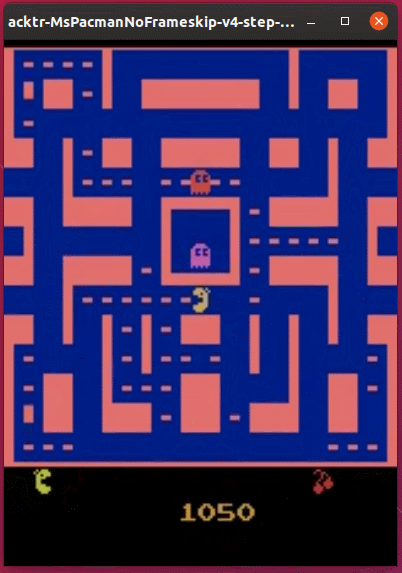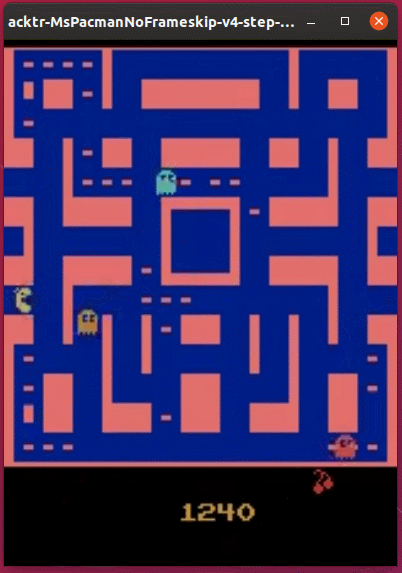
DQN、PPO2、ACER、ACKTRと試してきましたが、今回の学習アルゴリズム ACKTR が一番いい成績となりました。