以前パックマンを学習アルゴリズムDQNで攻略してみましたが、結果がいまいちだったので学習アルゴリズムを変えて実行してみます。
今回使用する学習アルゴリズムは PPO2 です。
このアルゴリズムを簡単に説明しますと、
- 高い報酬が得られる行動を優先し、低い報酬しか得られれない行動を避けるように方策を最適化する学習法 VPG を、
- 安定化するように改良した学習法 TRPO を、
- さらに計算量を削減するように改良した学習法 PPO1 で、
- GPUに対応している学習法 PPO2 です。
(Ubuntu 19.10で動作確認しています。)
PPO2でパックマンを攻略
次の条件で、学習済みモデルを実行している様子を動画ファイルに出力します。
- 環境
MsPacmanNoFrameskip-v4 - 学習アルゴリズム
PPO2 - ステップ数
1000
[コマンド]
1 | python3.7 -m utils.record_video --algo ppo2 --env MsPacmanNoFrameskip-v4 -n 1000 |
実行結果は次の通りです。
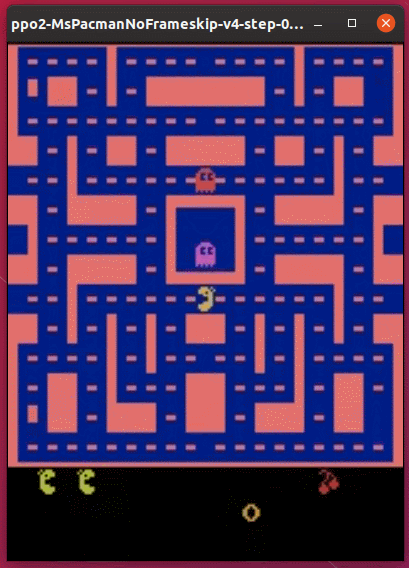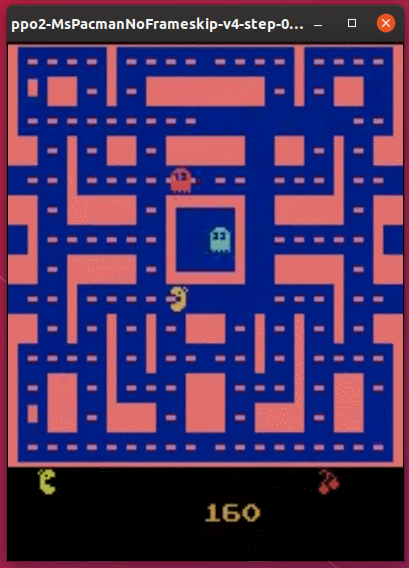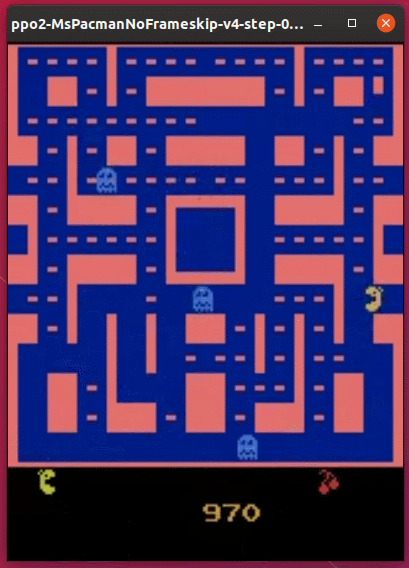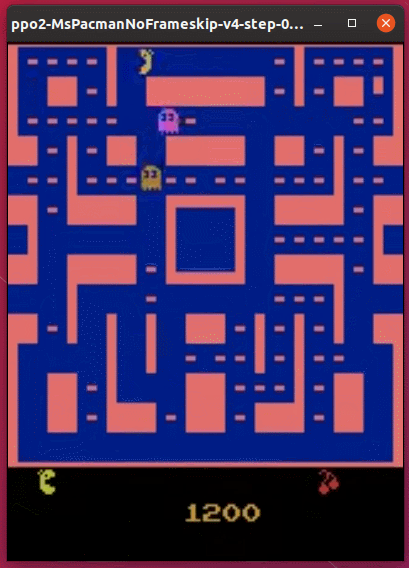
以前ためしたDQNよりは、だいぶ上手にプレイできているようです。