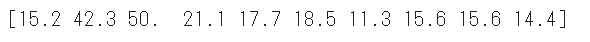ニューラルネットワークで数値データの予測を行う推定モデルを作成します。
まずは必要なパッケージをインポートします。
1 2 3 4 5 6 7 8 9 10 from tensorflow.keras.datasets import boston_housingfrom tensorflow.keras.layers import Activation, Dense, Dropoutfrom tensorflow.keras.models import Sequentialfrom tensorflow.keras.callbacks import EarlyStoppingfrom tensorflow.keras.optimizers import Adamimport pandas as pdimport numpy as npimport matplotlib.pyplot as plt%matplotlib inline
データセットの準備を行います。
各データの内容は次の通りです。
変数名
内容
train_data
訓練データの配列
train_labels
訓練ラベルの配列
test_data
テストデータの配列
test_labels
テストラベルの配列
1 2 (train_data, train_labels), (test_data, test_labels) = boston_housing.load_data()
データセットのシェイプを確認します。
1 2 3 4 5 print (train_data.shape)print (train_labels.shape)print (test_data.shape)print (test_labels.shape)
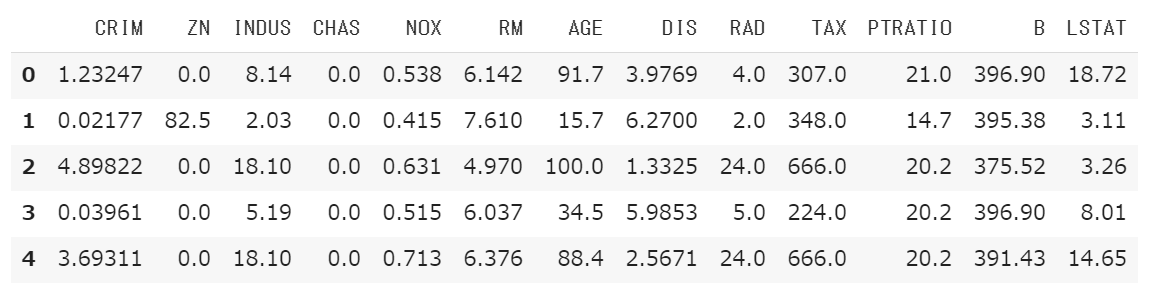
訓練データの先頭10件を表示します。
1 2 3 4 column_names = ['CRIM' , 'ZN' , 'INDUS' , 'CHAS' , 'NOX' , 'RM' , 'AGE' , 'DIS' , 'RAD' , 'TAX' , 'PTRATIO' , 'B' , 'LSTAT' ] df = pd.DataFrame(train_data, columns=column_names) df.head()
訓練ラベルの先頭10件を表示します。
1 2 print (train_labels[0 :10 ])
学習前の準備として、訓練データと訓練ラベルをシャッフルします。
1 2 3 4 order = np.argsort(np.random.random(train_labels.shape)) train_data = train_data[order] train_labels = train_labels[order]
訓練データとテストデータの正規化を行います。
具体的には平均0、分散1で正規化を行います。
1 2 3 4 5 mean = train_data.mean(axis=0 ) std = train_data.std(axis=0 ) train_data = (train_data - mean) / std test_data = (test_data - mean) / std
データセットのデータが平均0、分散1になっていることを確認します。
1 2 3 4 column_names = ['CRIM' , 'ZN' , 'INDUS' , 'CHAS' , 'NOX' , 'RM' , 'AGE' , 'DIS' , 'RAD' , 'TAX' , 'PTRATIO' , 'B' , 'LSTAT' ] df = pd.DataFrame(train_data, columns=column_names) df.head()
モデルを作成します。今回は全結合層を3つ重ねた簡単なモデルとなります。
1 2 3 4 5 model = Sequential() model.add(Dense(64 , activation='relu' , input_shape=(13 ,))) model.add(Dense(64 , activation='relu' )) model.add(Dense(1 ))
ニューラルネットワークモデルのコンパイルを行います。
損失関数 mse
最適化関数 Adam
評価指標 mae
1 2 model.compile (loss='mse' , optimizer=Adam(lr=0.001 ), metrics=['mae' ])
EarlyStoppingの準備を行います。
1 2 early_stop = EarlyStopping(monitor='val_loss' , patience=30 )
学習を行います。callbacksにEarlyStoppingを指定しています。
1 2 history = model.fit(train_data, train_labels, epochs=500 , validation_split=0.2 , callbacks=[early_stop])
学習中に出力される情報の意味は次の通りです。
情報
説明
loss
訓練データの誤差です。0に近いほどよい結果となります。
mean_absolute_error
訓練データの平均絶対誤差です。0に近いほどよい結果となります。
val_loss
検証データの誤差です。0に近いほどよい結果となります。
val_mean_absolute_error
検証データの平均絶対誤差です。0に近いほどよい結果となります。
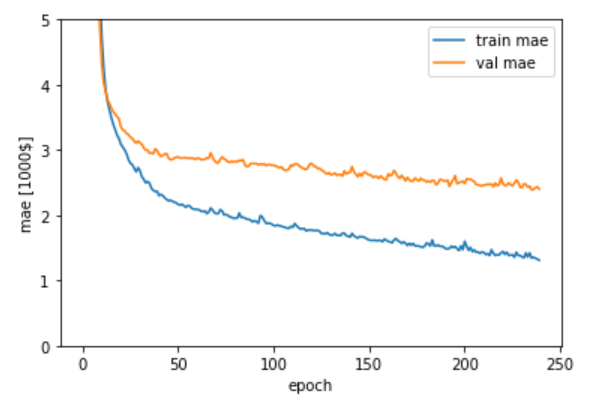
上記のデータうち、訓練データの平均絶対誤差(mae)と検証データの平均絶対誤差(val_mae)をグラフ表示します。
1 2 3 4 5 6 7 8 plt.plot(history.history['mean_absolute_error' ], label='train mae' ) plt.plot(history.history['val_mean_absolute_error' ], label='val mae' ) plt.xlabel('epoch' ) plt.ylabel('mae [1000$]' ) plt.legend(loc='best' ) plt.ylim([0 ,5 ]) plt.show()
テストデータとテストラベルを推定モデルに渡して評価を行い、平均絶対誤差を算出します。
1 2 3 test_loss, test_mae = model.evaluate(test_data, test_labels) print ('loss:{:.3f}\nmae: {:.3f}' .format (test_loss, test_mae))
平均絶対誤差は2.655となりました。
テストデータの先頭10件の推論を行い、予測結果を出力します。
1 2 3 4 5 6 print (np.round (test_labels[0 :10 ]))test_predictions = model.predict(test_data[0 :10 ]).flatten() print (np.round (test_predictions))
実際の価格に近い価格が推論されているような気がします。
(Google Colaboratory で動作確認しています。)
参考
AlphaZero 深層学習・強化学習・探索 人工知能プログラミング実践入門 サポートページ