手書き数字を分類するためにニューラルネットワークを作成し、実際の数字を推論するモデルを作ります。
まずは必要なパッケージをインポートします。
1 | # パッケージのインポート |
データセットの準備を行います。
各データの内容は次の通りです。
| 変数名 | 内容 |
|---|---|
| train_images | 訓練画像の配列 |
| train_labels | 訓練ラベルの配列 |
| test_images | テスト画像の配列 |
| test_labels | テストラベルの配列 |
1 | # データセットの準備 |

データセットのシェイプを確認します。
1 | # データセットのシェイプの確認 |

訓練画像データは60000×画像サイズ(28×28)です。
訓練ラベルデータは60000の1次元配列となります。
データセットの画像を確認するために先頭の10件を表示します。
1 | # データセットの画像の確認 |

データセットのラベルを確認するために先頭の10件を表示します。
1 | # データセットのラベルの確認 |
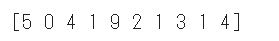
学習を開始する事前準備として、データセットをニューラルネットワークに適した形に変換します。
具体的には、画像データを28×28の2次元配列から1次元配列(786)に変換します。
1 | # データセットの画像の前処理 |

ラベルデータに関しても、ニューラルネットワークに適した形に変換します。
具体的にはone-hot表現に変えます。
one-hot表現とは、ある1要素が1でほかの要素が0である配列です。
ラベルが8の場合は[0, 0, 0, 0, 0, 0, 0, 0, 1, 0]という配列になります。
1 | # データセットのラベルの前処理 |

ニューラルネットワークのモデルを作成します。
入力層のシェイプは画像データに合わせて786で、出力層はラベルデータに合わせて10とします。
ユニット数と隠れ層の数は自由に決められますが今回はユニット数256と隠れ層128としました。
層とユニット数を増やすと複雑な特徴をとらえることができるようになる半面、学習時間が多くかかるようになってしまいます。
またユニット数が多くなると重要性の低い特徴を抽出して過学習になってしまう可能性があります。
Dropoutは過学習を防いでモデルの精度をあげるための手法となります。
任意の層のユニットをランダムに無効にして特定ニューロンへの依存を防ぎ汎化性能を上げます。
活性化関数は結合層の後に適用する関数で層からの出力に対して特定の関数を経由し最終的な出力値を決めます。活性化関数を使用することで線形分離不可能なデータも分類することができるようになります。
1 | # モデルの作成 |
ニューラルネットワークのモデルをコンパイルします。
- 損失関数 [loss]
モデルの予測値と正解データの誤差を計算する関数です。 - 最適化関数 [optimizer]
損失関数の結果が0に近づくように重みパラメータとバイアスを最適化する関数です。 - 評価指標 [metrics]
モデル性能を測定するための指標です。測定結果は、学習を行うfit()の戻り値に格納されます。
1 | # コンパイル |
訓練画像と訓練モデルを使って学習を実行します。
1 | # 学習 |

学習中に出力される情報の意味は次の通りです。
| 情報 | 説明 |
|---|---|
| loss | 訓練データの誤差です。0に近いほどよい結果となります。 |
| acc | 訓練データの正解率です。1に近いほどよい結果となります。 |
| val_loss | 検証データの誤差です。0に近いほどよい結果となります。 |
| val_acc | 検証データの正解率です。1に近いほどよい結果となります。 |
上記のデータうち、訓練データの正解率(acc)と検証データの正解率(val_acc)をグラフ表示します。
1 | # グラフの表示 |
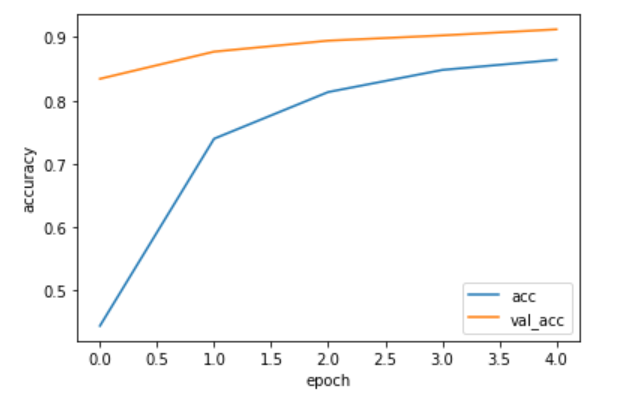
テスト画像とテストラベルをモデルに渡して評価を行います。
1 | # 評価 |

正解率は91.0%となりました。
先頭10件のテスト画像の推論を行い、画像データと予測結果を合わせて表示します。
1 | # 推論する画像の表示 |
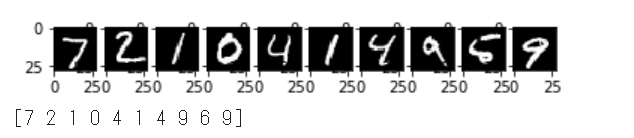
90%の正解率であることが確認できます。
(Google Colaboratoryで動作確認しています。)
参考
AlphaZero 深層学習・強化学習・探索 人工知能プログラミング実践入門 サポートページ