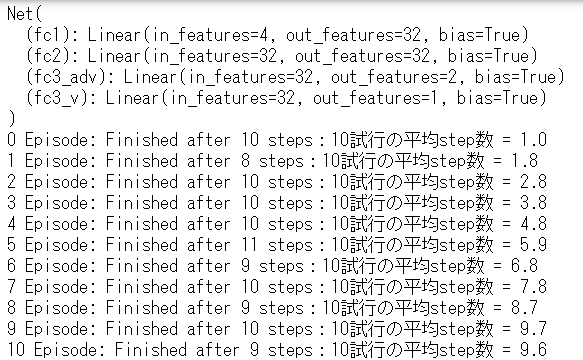
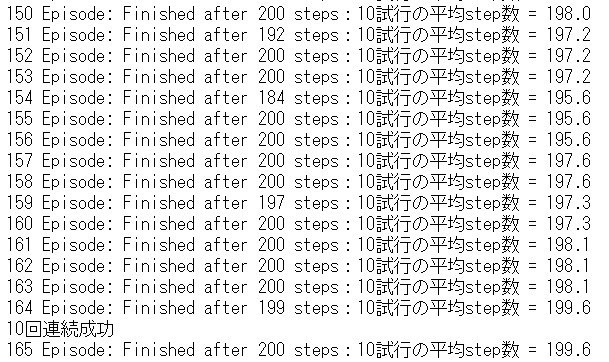
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
|
import random
import torch
from torch import nn
from torch import optim
import torch.nn.functional as F
BATCH_SIZE = 32
CAPACITY = 10000
class Brain:
def __init__(self, num_states, num_actions):
self.num_actions = num_actions
self.memory = ReplayMemory(CAPACITY)
n_in, n_mid, n_out = num_states, 32, num_actions
self.main_q_network = Net(n_in, n_mid, n_out)
self.target_q_network = Net(n_in, n_mid, n_out)
print(self.main_q_network)
self.optimizer = optim.Adam(
self.main_q_network.parameters(), lr=0.0001)
def replay(self):
'''Experience Replayでネットワークの結合パラメータを学習'''
if len(self.memory) < BATCH_SIZE:
return
self.batch, self.state_batch, self.action_batch, self.reward_batch, self.non_final_next_states = self.make_minibatch()
self.expected_state_action_values = self.get_expected_state_action_values()
self.update_main_q_network()
def decide_action(self, state, episode):
'''現在の状態に応じて、行動を決定する'''
epsilon = 0.5 * (1 / (episode + 1))
if epsilon <= np.random.uniform(0, 1):
self.main_q_network.eval()
with torch.no_grad():
action = self.main_q_network(state).max(1)[1].view(1, 1)
else:
action = torch.LongTensor(
[[random.randrange(self.num_actions)]])
return action
def make_minibatch(self):
'''2. ミニバッチの作成'''
transitions = self.memory.sample(BATCH_SIZE)
batch = Transition(*zip(*transitions))
state_batch = torch.cat(batch.state)
action_batch = torch.cat(batch.action)
reward_batch = torch.cat(batch.reward)
non_final_next_states = torch.cat([s for s in batch.next_state if s is not None])
return batch, state_batch, action_batch, reward_batch, non_final_next_states
def get_expected_state_action_values(self):
'''3. 教師信号となるQ(s_t, a_t)値を求める'''
self.main_q_network.eval()
self.target_q_network.eval()
self.state_action_values = self.main_q_network(
self.state_batch).gather(1, self.action_batch)
non_final_mask = torch.ByteTensor(tuple(map(lambda s: s is not None,
self.batch.next_state)))
next_state_values = torch.zeros(BATCH_SIZE)
a_m = torch.zeros(BATCH_SIZE).type(torch.LongTensor)
a_m[non_final_mask] = self.main_q_network(
self.non_final_next_states).detach().max(1)[1]
a_m_non_final_next_states = a_m[non_final_mask].view(-1, 1)
next_state_values[non_final_mask] = self.target_q_network(
self.non_final_next_states).gather(1, a_m_non_final_next_states).detach().squeeze()
expected_state_action_values = self.reward_batch + GAMMA * next_state_values
return expected_state_action_values
def update_main_q_network(self):
'''4. 結合パラメータの更新'''
self.main_q_network.train()
loss = F.smooth_l1_loss(self.state_action_values,
self.expected_state_action_values.unsqueeze(1))
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
def update_target_q_network(self):
'''Target Q-NetworkをMainと同じにする'''
self.target_q_network.load_state_dict(self.main_q_network.state_dict())
|