CartPoleをQ学習で制御していきます。
実装するクラスは下記の3つです。
- Agentクラス
カートを表します。
Q関数を更新する関数と次の行動を決定する関数があります。
Brainクラスのオブジェクトをメンバーに持ちます。 - Brainクラス
Agentの頭脳となるクラスです。
Q学習を実装します。
状態を離散化する関数とQテーブルを更新する関数とQテーブルから行動を決定する関数があります。 - Environmentクラス
OpenAI Gymの実行環境です。
まず必要なパッケージをインポートします。
1 | # パッケージのimport |
動画を描画するための関数を定義します。
1 | # 動画の描画関数の宣言 |
各定数を定義します。
CartPole-v0は200ステップ 棒が立ち続ければゲーム攻略となります。(MAX_STEPS=200)
1 | # 定数の設定 |
Agentクラスを実装します。
初期関数initでCartPoleの状態数と行動数を受け取り、自分の頭脳となるBrainクラスを生成します。
1 | class Agent: |
Brainクラスを実装します。
Qテーブルの更新と行動の決定を行います。
試行回数が少ないときは探索行動が多くなるようなε-greedy法としています。
1 | class Brain: |
Environmentクラスを定義します。
10回連続で195ステップ以上棒が立ち続ければ学習成功としています。
成功後に動画保存のため1回再実行しています。
1 | class Environment: |
Environmentクラスのオブジェクトを生成し、関数runを実行します。
1 | # main |
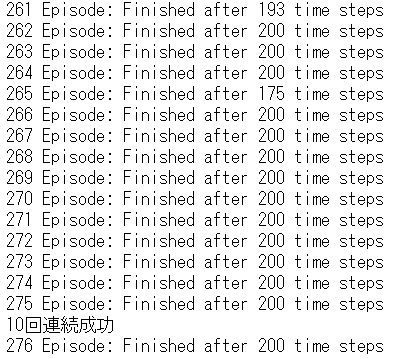
275エピソードで学習が完了しています。(195ステップ以上を10エピソード連続で成功)
強化学習後のプレイ動画は’3_4movie_cartpole.mp4’ファイルで保存されています。
棒が倒れずにうまくバランスがとれていることが分かります。
参考 > つくりながら学ぶ!深層強化学習 サポートページ