AlphaZeroのベースとなるモンテカルロ木探索を作成します。
ニューラルネットワークで「方策」と「価値」を取得します。
「方策」はアーク評価値の計算、「価値」は累計価値の更新に利用します。
まず必要なパッケージをインポートします。
1 | # ==================== |
ニューラルネットワークの推論を行います。
- 推論のために入力データのシェイプを変換します。
自分の石の配置と相手の石の配置を(1, 3, 3, 2)に変換します。 - 推論を行います。
model.predict()を使います。 - 方策を取得します。
合法手のみ抽出し、合計で割って合法手のみの確率分布に変換します。 - 価値を取得します。
価値の配列から値のみを抽出します。
1 | # 推論 |
ノードのリストを試行回数のリストに変換します。
1 | # ノードのリストを試行回数のリストに変換 |
モンテカルロ木探索のスコアを取得します。
- モンテカルロ木探索のノードを定義します。
- 現在の局面のノードを作成します。
- 複数回の評価を実行します。
4.合法手の確率分布を返します。
1 | # モンテカルロ木探索のスコアの取得 |
モンテカルロ木探索で行動を選択します。
1 | # モンテカルロ木探索で行動選択 |
ボルツマン分布によるバラつきを付加します。
1 | # ボルツマン分布 |
動作確認のためにモンテカルロ木探索行動選択「pv_mcts_action」を使ってゲーム終了まで実行します。
1 | # 動作確認 |
実行結果は下記の通りです。
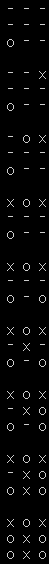
今回は引き分けとなりました。
参考
AlphaZero 深層学習・強化学習・探索 人工知能プログラミング実践入門 サポートページ