三目並べをミニマックス法で解いていきます。
ミニマックス法は、自分は自分にとって最善手を選び、相手は自分にとって最悪手を選ぶと仮定して最善手を探すアルゴリズムです。
ポイントは次の通りです。
- next()は行動に応じて次の状態を取得する。
- 行動は石を配置するマスの位置を0~8で指定する。
- legal_actions()は選択可能な行動を取得します。
1 | # 三目並べの作成 |
ランダムで行動選択する関数を実装します。
leagl_actions()で合法手を取得し、その中からランダムに手を選びます。
1 | # ランダムで行動選択 |
ランダムとランダムで三目並べを対戦させます。
ゲーム終了まで行動の取得と次の状態の取得を繰り返します。
1 | # ランダムとランダムで対戦 |
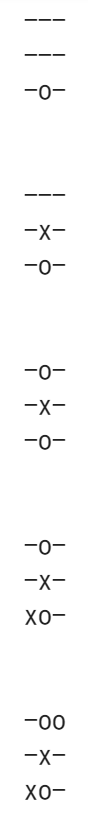
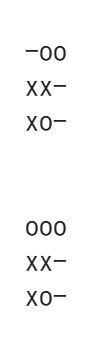
ミニマックス法で状態価値の計算を行います。
1 | # ミニマックス法で状態価値計算 |
ミニマックス法で状態に応じて行動を返す関数を実装します。
Stateを渡すと行動(石を置くマス:0~8)を返します。
1 | # ミニマックス法で行動選択 |
ミニマックス法とランダムで対戦します。
先手はmini_max_action()、後手はrandmo_action()を使います。
1 | # ミニマックス法とランダムで対戦 |
実行ごとに結果がかわるので複数回実行してみてください。
ただランダムが勝つことはありません。

(Google Colaboratoryで動作確認しています。)
参考
AlphaZero 深層学習・強化学習・探索 人工知能プログラミング実践入門 サポートページ