迷路ゲームをSarsaとQ-learningで解いていきます。
SarsaとQ-learningは価値反復法と呼ばれ、ある行動をとるたびに状態価値を増やす手法です。
(Sarsaは収束が遅い一方局所解に陥りにくく、Q-learningは収束が早い一方で局所解に陥りやすいと言われています。)
今回の強化学習のポイントは下記です。
- 目的はゴールすること。
- 状態は位置。
- 行動は上下左右の4種類。
- 報酬はゴールしたら+1。
- パラメータl更新間隔は行動1回ごと。
価値反復法の学習手順は次の通りです。
- ランダム行動の準備する。
- 行動価値関数を準備する。
- 行動に従って、次の状態を取得する。
- ランダムまたは行動価値関数に従って、行動を取得する。
- 行動価値関数を更新する。
- ゴールするまで3~5を繰り返す。
まずは必要なパッケージをインポートします。
1 | # パッケージのインポート |
迷路を作成します。
1 | # 迷路の作成 |
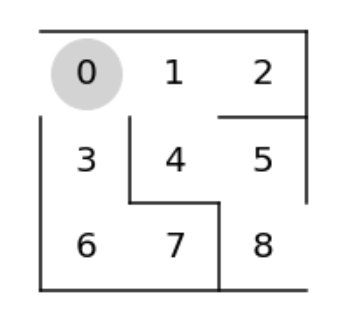
ランダム行動を準備します。
パラメータθと方策を作成し、np.random.choice()でばらつきを加えて作成します。
前回の方策勾配法とは違い、今回パラメータθと方策の更新はありません。
1 | # パラメータθの初期値の準備 |
パラメータθから方策のへの変換には単純な割合計算を行います。
1 | # パラメータθを方策に変換 |
パラメータθの初期値を変換します。列の合計が1になっています。
1 | # パラメータθの初期値を方策に変換 |

行動価値関数を表形式で準備します。
学習前は行動価値関数は不明なので、移動可能が方向は乱数、移動不可の方向は欠損値(np.nan)で初期化します。
1 | # 行動価値関数の準備 |

行動に従って次の状態を取得する関数を作成します。
1 | # 行動に従って次の状態を取得 |
確率ε(0以上1以下)でランダムに行動し、確率1-εで行動価値関数の行動を選択します。
1 | # ランダムまたは行動価値関数に従って行動を取得 |
Sarsaの行動価値関数の更新は、パラメータθに学習係数とTD誤差を掛けた値を加算します。
1 | # Sarsaによる行動価値関数の更新 |
Q-learningの行動価値関数の更新は、次ステップの価値最大の行動を使用します。
(Sarsaと異なりランダム性を含みません)
1 | # Q学習による行動価値関数の更新 |
1エピソードを実行して履歴と行動価値を取得します。
履歴は[状態, 行動]のリストです。
Sarsaの場合は行動価値関数としてsarsa()を使い、Q-learnigの場合はq-learning()を使います。
1 | # 1エピソードの実行 |
エピソードを繰り返し実行して学習を行います。今回は10回エピソードを実行しています。
1 | epsilon = 0.5 # ε-greedy法のεの初期値 |
SarsaとQ-learningでそれぞれ最短ステップの4に収束していることがわかります。
またSarsaよりQ-learningの方が収束が早いこともわかります。
最後の履歴をもとにアニメーション表示を行ってみます。
(Sarsa、Q-learningともに最終的には同じ結果になります。)
1 | # アニメーションの定期処理を行う関数 |
(Google Colaboratoryで動作確認しています。)
参考
AlphaZero 深層学習・強化学習・探索 人工知能プログラミング実践入門 サポートページ