迷路ゲームを方策勾配法で解いていきます。
方策勾配法では成功時の行動を重要と考え、その行動を多く取り入れる手法です。
- 目的はゴールすること。
- 状態は位置。
- 行動は上下左右の4種類。
- 報酬はゴールした行動を重要視。
- パラメータ更新間隔は1エピソード(ゴールするまで)
学習手順は次の通りです。
- パラメータθを準備。
- パラメータθを方策に変換。
- 方策に従って、行動をゴールするまで繰り返す。
- 成功した行動を多く取り入れるようにパラメータθを更新する。
- 方策の変化量が閾値以下になるまで2~4を繰り返す。
パラメータθは深層学習の重みパラメータにあたるものです。
まずは必要なパッケージをインポートします。
1 | # パッケージのインポート |
迷路を作成します。
1 | # 迷路の作成 |
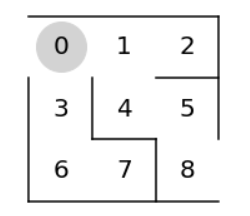
パラメータθを準備します。
学習前は正しいパラメータθは不明なので、移動可能な方向は1、移動不可な方向はnp.nan(欠損値)で初期化します。
スタートのマスはインデックス0で、ゴールのマス(インデックス8)は存在しません。
1 | # パラメータθの初期値の準備 |
パラメータθを方策に変換します。
変換関数にはソフトマックス関数を利用します。マスごとに合計を1になる実数値に落とし込む関数です。
例)[np,nan, 1, 1, np.nan] -> [0, 0.5, 0.5, 0]
1 | # パラメータθを方策に変換 |
パラメータθの初期値を方策に変換します。
1 | # パラメータθの初期値を方策に変換 |
列の合計が1になっていることが分かります。
方策に従って行動を取得します。
np.random.choice()にて引数pの確率分布に従って、配列の要素をランダムに返します。
1 | # 方策に従って行動を取得 |
行動に従って次の状態を取得する関数を定義します、
3 x 3 の迷路なので、左右移動は±1、上下移動は±3になります。
1 | # 行動に従って次の状態を取得 |
1エピソードを実行して、履歴を取得します。履歴は、[状態, 行動]のリストです。
1 | # 1エピソード実行して履歴取得 |
1エピソードの実行と履歴を確認します。
ゴールまでにどのような経路をたどり、何ステップかかったかを把握することができます。
1 | # 1エピソードの実行と履歴の確認 |

パラメータθを更新します。
パラメータθに「学習係数」と「パラメータθの変化量」を掛けた値を加算します。
学習係数は1回の学習で更新される大きさです。
1 | def update_theta(theta, pi, s_a_history): |
エピソードを繰り返し実行して学習を行います。
1 | stop_epsilon = 10**-3 # しきい値 |

(中略)
ゴールへの最短ステップ数である4に少しずつ近づいているのが分かります。
最後の履歴をもとにアニメーション表示を行ってみます。
# アニメーションの定期処理を行う関数
def animate(i):
state = s_a_history[i][0]
circle.set_data((state % 3) + 0.5, 2.5 - int(state / 3))
return circle
# アニメーションの表示
anim = animation.FuncAnimation(fig, animate, \
frames=len(s_a_history), interval=1000, repeat=False)
HTML(anim.to_jshtml())```
{% youtube BUoy31PYMMY %}
([Google Colaboratory](https://colab.research.google.com/notebooks/welcome.ipynb)で動作確認しています。)
参考
> <cite>AlphaZero 深層学習・強化学習・探索 人工知能プログラミング実践入門 <a href="https://www.borndigital.co.jp/book/14383.html" > サポートページ</a> </cite>