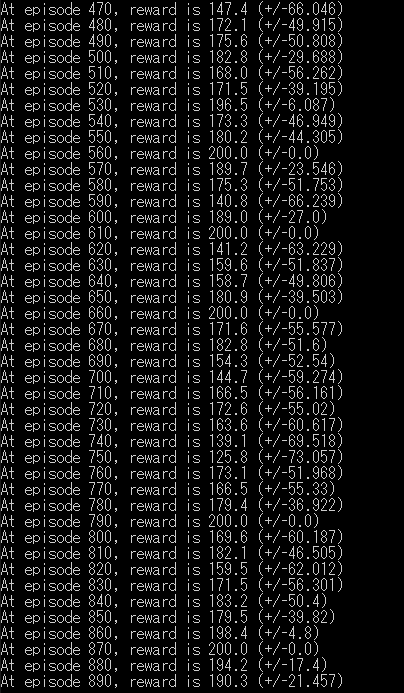
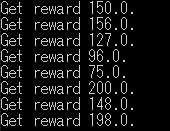
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
| import random
import argparse
from collections import deque
import numpy as np
import tensorflow as tf
from tensorflow.python import keras as K
from PIL import Image
import gym
import gym_ple
from fn_framework import FNAgent, Trainer, Observer, Experience
class ActorCriticAgent(FNAgent):
def __init__(self, epsilon, actions):
super().__init__(epsilon, actions)
self._updater = None
@classmethod
def load(cls, env, model_path, epsilon=0.0001):
actions = list(range(env.action_space.n))
agent = cls(epsilon, actions)
agent.model = K.models.load_model(model_path, custom_objects={
"SampleLayer": SampleLayer})
agent.initialized = True
return agent
def initialize(self, experiences, optimizer):
feature_shape = experiences[0].s.shape
self.make_model(feature_shape)
self.set_updater(optimizer)
self.initialized = True
def make_model(self, feature_shape):
normal = K.initializers.glorot_normal()
model = K.Sequential()
model.add(K.layers.Conv2D(
32, kernel_size=8, strides=4, padding="same",
input_shape=feature_shape,
kernel_initializer=normal, activation="relu"))
model.add(K.layers.Conv2D(
64, kernel_size=4, strides=2, padding="same",
kernel_initializer=normal, activation="relu"))
model.add(K.layers.Conv2D(
64, kernel_size=3, strides=1, padding="same",
kernel_initializer=normal, activation="relu"))
model.add(K.layers.Flatten())
model.add(K.layers.Dense(256, kernel_initializer=normal,
activation="relu"))
actor_layer = K.layers.Dense(len(self.actions),
kernel_initializer=normal)
action_evals = actor_layer(model.output)
actions = SampleLayer()(action_evals)
critic_layer = K.layers.Dense(1, kernel_initializer=normal)
values = critic_layer(model.output)
self.model = K.Model(inputs=model.input,
outputs=[actions, action_evals, values])
def set_updater(self, optimizer,
value_loss_weight=1.0, entropy_weight=0.1):
actions = tf.placeholder(shape=(None), dtype="int32")
rewards = tf.placeholder(shape=(None), dtype="float32")
_, action_evals, values = self.model.output
neg_logs = tf.nn.sparse_softmax_cross_entropy_with_logits(
logits=action_evals, labels=actions)
advantages = rewards - values
policy_loss = tf.reduce_mean(neg_logs * tf.nn.softplus(advantages))
value_loss = tf.losses.mean_squared_error(rewards, values)
action_entropy = tf.reduce_mean(self.categorical_entropy(action_evals))
loss = policy_loss + value_loss_weight * value_loss
loss -= entropy_weight * action_entropy
updates = optimizer.get_updates(loss=loss,
params=self.model.trainable_weights)
self._updater = K.backend.function(
inputs=[self.model.input,
actions, rewards],
outputs=[loss,
policy_loss,
tf.reduce_mean(neg_logs),
tf.reduce_mean(advantages),
value_loss,
action_entropy],
updates=updates)
def categorical_entropy(self, logits):
"""
From OpenAI baseline implementation
https://github.com/openai/baselines/blob/master/baselines/common/distributions.py#L192
"""
a0 = logits - tf.reduce_max(logits, axis=-1, keepdims=True)
ea0 = tf.exp(a0)
z0 = tf.reduce_sum(ea0, axis=-1, keepdims=True)
p0 = ea0 / z0
return tf.reduce_sum(p0 * (tf.log(z0) - a0), axis=-1)
def policy(self, s):
if np.random.random() < self.epsilon or not self.initialized:
return np.random.randint(len(self.actions))
else:
action, action_evals, values = self.model.predict(np.array([s]))
return action[0]
def estimate(self, s):
action, action_evals, values = self.model.predict(np.array([s]))
return values[0][0]
def update(self, states, actions, rewards):
return self._updater([states, actions, rewards])
class SampleLayer(K.layers.Layer):
def __init__(self, **kwargs):
self.output_dim = 1
super(SampleLayer, self).__init__(**kwargs)
def build(self, input_shape):
super(SampleLayer, self).build(input_shape)
def call(self, x):
noise = tf.random_uniform(tf.shape(x))
return tf.argmax(x - tf.log(-tf.log(noise)), axis=1)
def compute_output_shape(self, input_shape):
return (input_shape[0], self.output_dim)
class ActorCriticAgentTest(ActorCriticAgent):
def make_model(self, feature_shape):
normal = K.initializers.glorot_normal()
model = K.Sequential()
model.add(K.layers.Dense(64, input_shape=feature_shape,
kernel_initializer=normal, activation="relu"))
model.add(K.layers.Dense(64, kernel_initializer=normal,
activation="relu"))
actor_layer = K.layers.Dense(len(self.actions),
kernel_initializer=normal)
action_evals = actor_layer(model.output)
actions = SampleLayer()(action_evals)
critic_layer = K.layers.Dense(1, kernel_initializer=normal)
values = critic_layer(model.output)
self.model = K.Model(inputs=model.input,
outputs=[actions, action_evals, values])
class CatcherObserver(Observer):
def __init__(self, env, width, height, frame_count):
super().__init__(env)
self.width = width
self.height = height
self.frame_count = frame_count
self._frames = deque(maxlen=frame_count)
def transform(self, state):
grayed = Image.fromarray(state).convert("L")
resized = grayed.resize((self.width, self.height))
resized = np.array(resized).astype("float")
normalized = resized / 255.0
if len(self._frames) == 0:
for i in range(self.frame_count):
self._frames.append(normalized)
else:
self._frames.append(normalized)
feature = np.array(self._frames)
feature = np.transpose(feature, (1, 2, 0))
return feature
class ActorCriticTrainer(Trainer):
def __init__(self, buffer_size=50000, batch_size=32,
gamma=0.99, initial_epsilon=0.1, final_epsilon=1e-3,
learning_rate=1e-3, report_interval=10,
log_dir="", file_name=""):
super().__init__(buffer_size, batch_size, gamma,
report_interval, log_dir)
self.file_name = file_name if file_name else "a2c_agent.h5"
self.initial_epsilon = initial_epsilon
self.final_epsilon = final_epsilon
self.learning_rate = learning_rate
self.d_experiences = deque(maxlen=self.buffer_size)
self.training_episode = 0
self.losses = {}
self._max_reward = -10
def train(self, env, episode_count=900, initial_count=10,
test_mode=False, render=False, observe_interval=100):
actions = list(range(env.action_space.n))
if not test_mode:
agent = ActorCriticAgent(1.0, actions)
else:
agent = ActorCriticAgentTest(1.0, actions)
observe_interval = 0
self.training_episode = episode_count
self.train_loop(env, agent, episode_count, initial_count, render,
observe_interval)
return agent
def episode_begin(self, episode, agent):
self.losses = {}
for key in ["loss", "loss_policy", "loss_action", "loss_advantage",
"loss_value", "entropy"]:
self.losses[key] = []
self.experiences = []
def step(self, episode, step_count, agent, experience):
if self.training:
loss, lp, ac, ad, vl, en = agent.update(*self.make_batch())
self.losses["loss"].append(loss)
self.losses["loss_policy"].append(lp)
self.losses["loss_action"].append(ac)
self.losses["loss_advantage"].append(ad)
self.losses["loss_value"].append(vl)
self.losses["entropy"].append(en)
def make_batch(self):
batch = random.sample(self.d_experiences, self.batch_size)
states = [e.s for e in batch]
actions = [e.a for e in batch]
rewards = [e.r for e in batch]
return states, actions, rewards
def begin_train(self, episode, agent):
self.logger.set_model(agent.model)
agent.epsilon = self.initial_epsilon
self.training_episode -= episode
print("Done initialization. From now, begin training!")
def episode_end(self, episode, step_count, agent):
rewards = [e.r for e in self.experiences]
self.reward_log.append(sum(rewards))
if not agent.initialized:
optimizer = K.optimizers.Adam(lr=self.learning_rate, clipnorm=5.0)
agent.initialize(self.experiences, optimizer)
discounteds = []
for t, r in enumerate(rewards):
future_r = [_r * (self.gamma ** i) for i, _r in
enumerate(rewards[t:])]
_r = sum(future_r)
discounteds.append(_r)
for i, e in enumerate(self.experiences):
s, a, r, n_s, d = e
d_r = discounteds[i]
d_e = Experience(s, a, d_r, n_s, d)
self.d_experiences.append(d_e)
if not self.training and len(self.d_experiences) == self.buffer_size:
self.begin_train(i, agent)
self.training = True
if self.training:
reward = sum(rewards)
self.logger.write(self.training_count, "reward", reward)
self.logger.write(self.training_count, "reward_max", max(rewards))
self.logger.write(self.training_count, "epsilon", agent.epsilon)
for k in self.losses:
loss = sum(self.losses[k]) / step_count
self.logger.write(self.training_count, "loss/" + k, loss)
if reward > self._max_reward:
agent.save(self.logger.path_of(self.file_name))
self._max_reward = reward
diff = (self.initial_epsilon - self.final_epsilon)
decay = diff / self.training_episode
agent.epsilon = max(agent.epsilon - decay, self.final_epsilon)
if self.is_event(episode, self.report_interval):
recent_rewards = self.reward_log[-self.report_interval:]
self.logger.describe("reward", recent_rewards, episode=episode)
def main(play, is_test):
file_name = "a2c_agent.h5" if not is_test else "a2c_agent_test.h5"
trainer = ActorCriticTrainer(file_name=file_name)
path = trainer.logger.path_of(trainer.file_name)
agent_class = ActorCriticAgent
if is_test:
print("Train on test mode")
obs = gym.make("CartPole-v0")
agent_class = ActorCriticAgentTest
else:
env = gym.make("Catcher-v0")
obs = CatcherObserver(env, 80, 80, 4)
trainer.learning_rate = 7e-5
if play:
agent = agent_class.load(obs, path)
agent.play(obs, episode_count=10, render=True)
else:
trainer.train(obs, test_mode=is_test)
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="A2C Agent")
parser.add_argument("--play", action="store_true", help="play with trained model")
parser.add_argument("--test", action="store_true", help="train by test mode")
args = parser.parse_args()
main(args.play, args.test)
|