これまで試してきた4手法(モンテカルロ法 / TD法 / SARSA / Actor Critic法)の結果一覧をまとめました。
まずおさらいとして検証モデルとして使用したのはOpenAI GymのFrozenLakeです。
4 x 4 マスの迷路でところどころに穴があいていて穴に落ちるとゲーム終了となります。
穴に落ちずにゴールに到着すると報酬が得られます。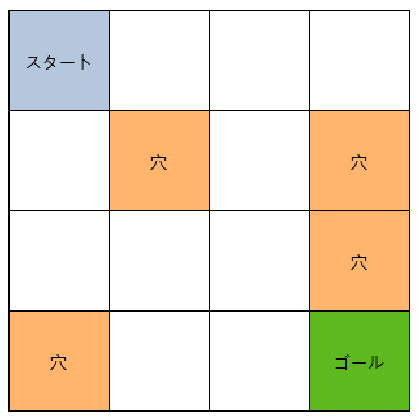
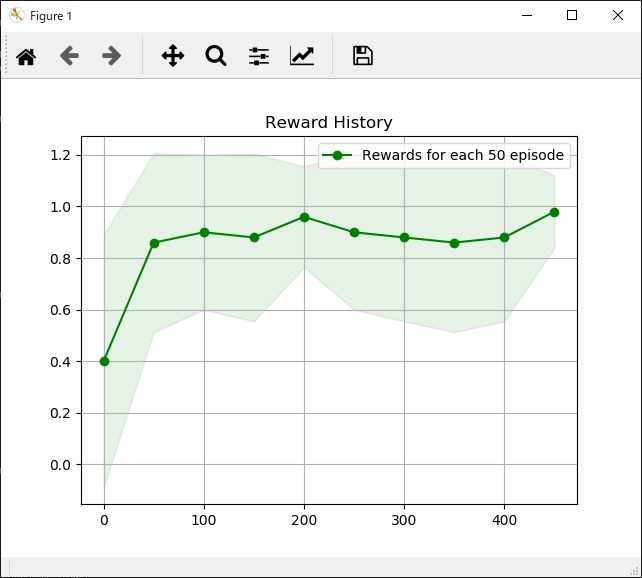
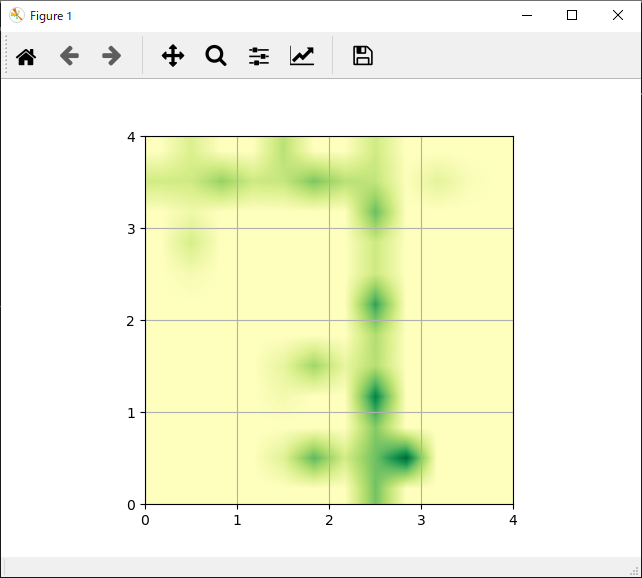
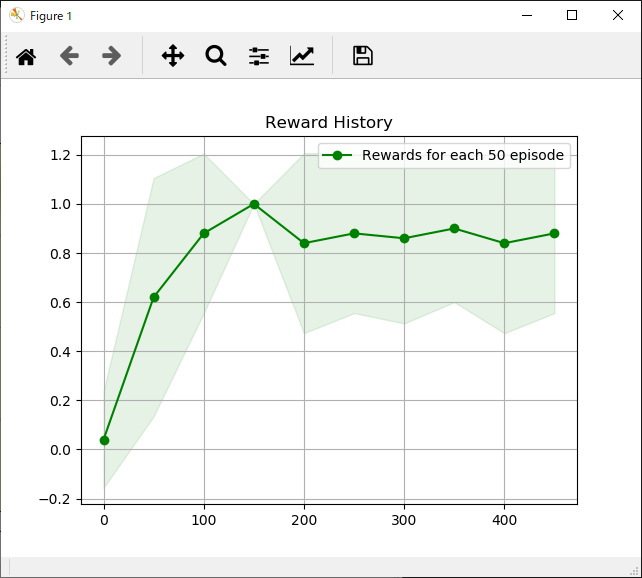
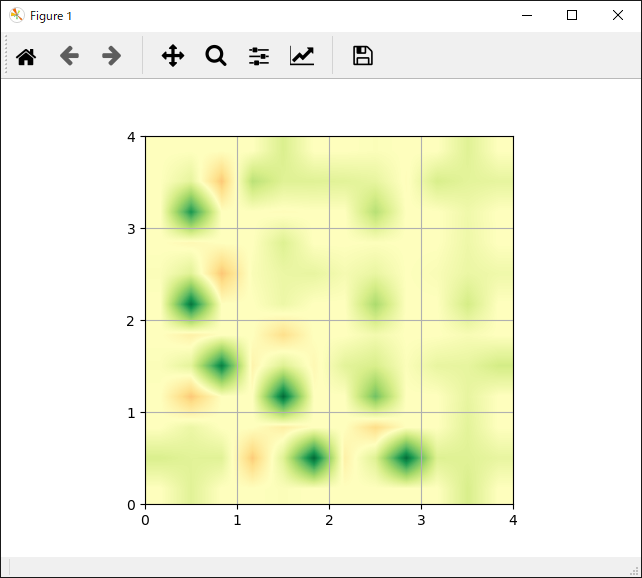
次に各手法ごとの「各行動の評価」と「獲得報酬平均」の結果一覧です。
| 各行動の評価 | 獲得報酬平均 |
|---|---|
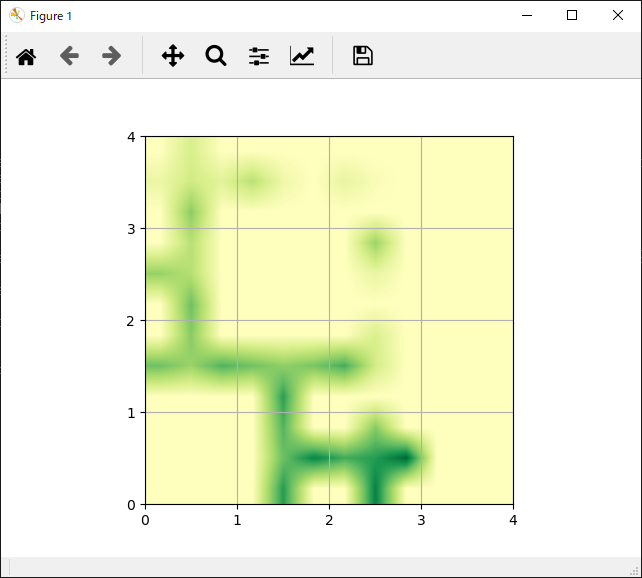 |
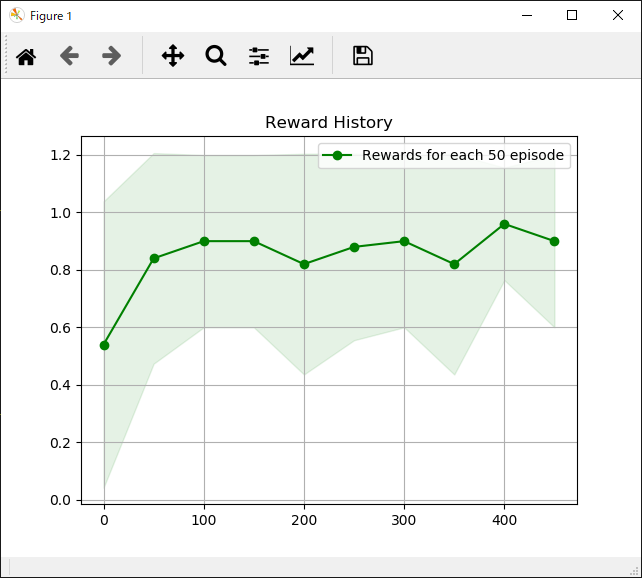 |
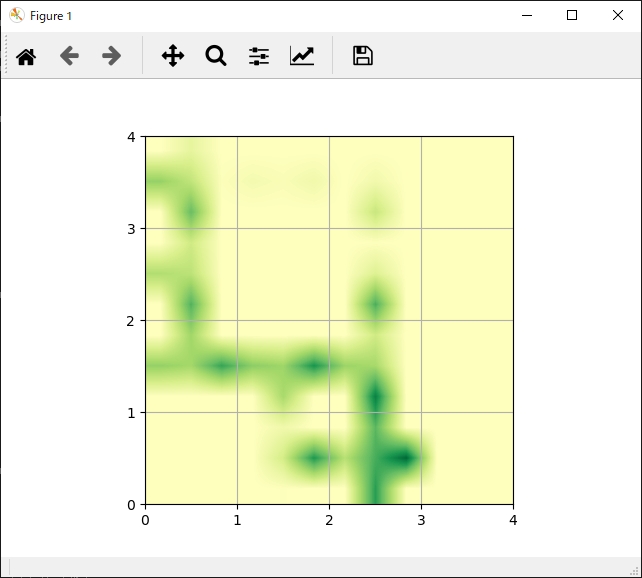 |
 |
 |
 |
 |
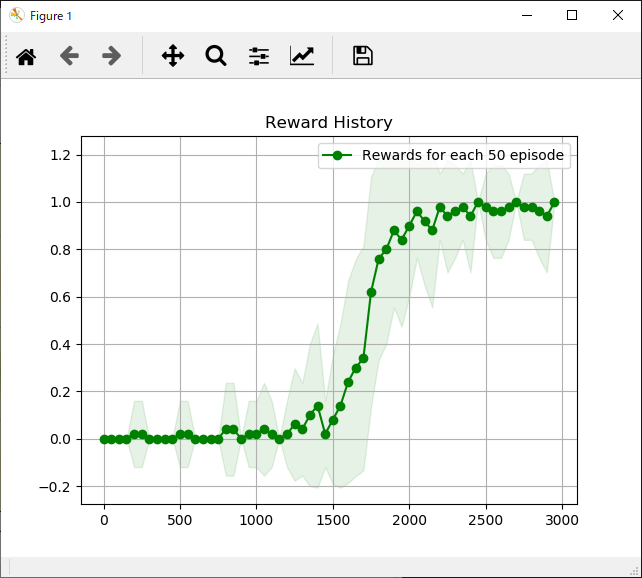 |
簡単に各手法を説明します。
モンテカルロ法
エピソードが終了してから評価を行う。Valueベース。TD法(Q-learning)
1ステップごとに評価を行う。Valueベース。SARSA
戦略に戻づいて行動を決定する。Policyベース。Actor Critic法
戦略と価値評価を相互に更新して学習する。ValueベースかつPolicyベース。
それぞれ特徴がありますが、学習までに時間がかかるものの最終的には一番獲得報酬が安定しているActor Critic法が個人的には好みです。
参考
Pythonで学ぶ強化学習 -入門から実践まで- サンプルコード