Actor Critic法による学習を試してみます。
Actor Critic法は、戦略担当(Actor)と価値評価担当(Critic)を相互に更新して学習する手法です。
まずはエージェントのベースになるクラスを実装します。(強化学習5・6 (モンテカルロ法・TD法)と同様です。)
1 | import numpy as np |
次に環境を扱うためのクラスを実装します。
(強化学習5・6 (モンテカルロ法・TD法)と同様です。)
1 | import numpy as np |
Actor Critic法での学習を実行します。
53行目で行動評価(Q値)の更新を行い、54行目で状態価値の更新を行っています。
ValueベースとPolicyベース両方の特性を持っていることになります。
1 | import numpy as np |
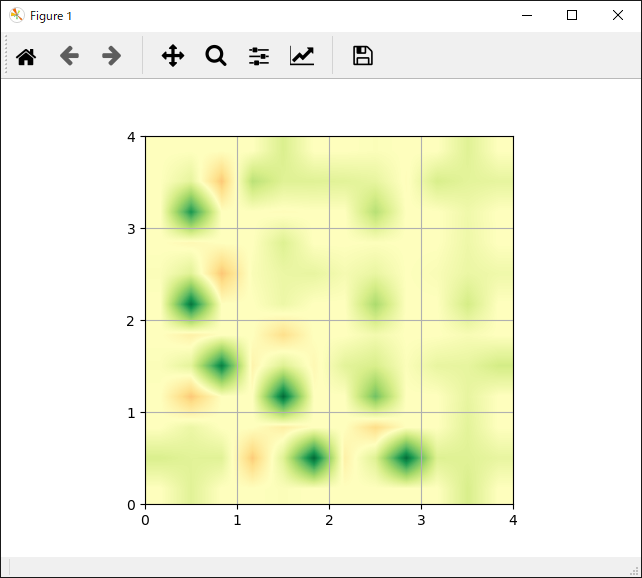
| FrozenLake | 各行動の評価 |
|---|---|
 |
 |
エピソード実行回数と獲得報酬平均の推移は次のようになります。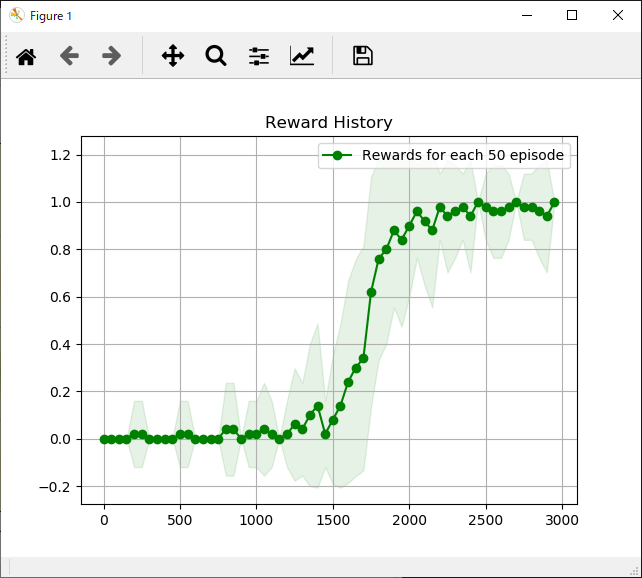
今まで試してきた手法より学習にかかるエピソード数は長くなっていますが、安定した報酬が得られるようになっています。
参考
Pythonで学ぶ強化学習 -入門から実践まで- サンプルコード