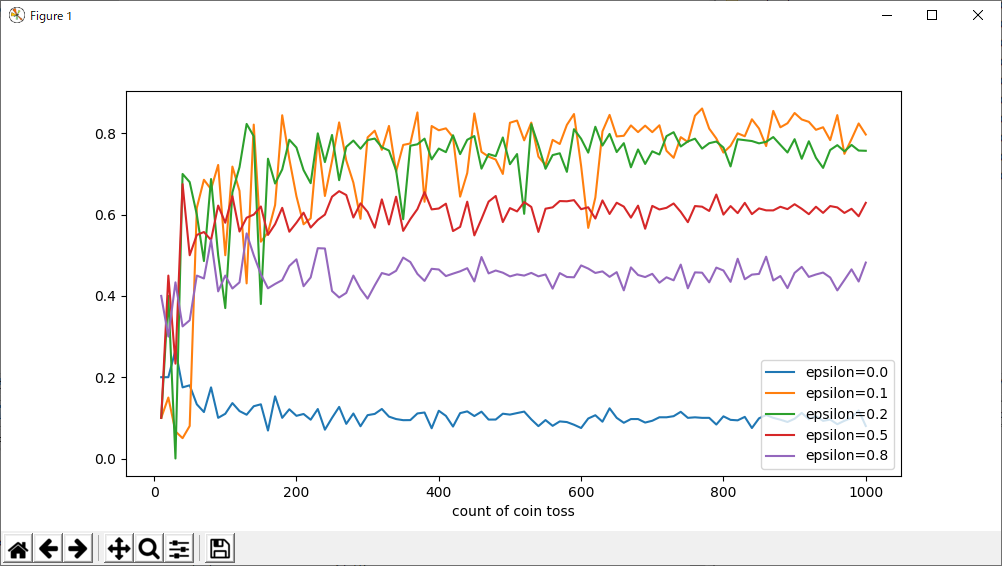
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
| import random
import numpy as np
class CoinToss():
def __init__(self, head_probs, max_episode_steps=30):
self.head_probs = head_probs
self.max_episode_steps = max_episode_steps
self.toss_count = 0
def __len__(self):
return len(self.head_probs)
def reset(self):
self.toss_count = 0
def step(self, action):
final = self.max_episode_steps - 1
if self.toss_count > final:
raise Exception("The step count exceeded maximum. Please reset env.")
else:
done = True if self.toss_count == final else False
if action >= len(self.head_probs):
raise Exception("The No.{} coin doesn't exist.".format(action))
else:
head_prob = self.head_probs[action]
if random.random() < head_prob:
reward = 1.0
else:
reward = 0.0
self.toss_count += 1
return reward, done
class EpsilonGreedyAgent():
def __init__(self, epsilon):
self.epsilon = epsilon
self.V = []
def policy(self):
coins = range(len(self.V))
if random.random() < self.epsilon:
return random.choice(coins)
else:
return np.argmax(self.V)
def play(self, env):
N = [0] * len(env)
self.V = [0] * len(env)
env.reset()
done = False
rewards = []
while not done:
selected_coin = self.policy()
reward, done = env.step(selected_coin)
rewards.append(reward)
n = N[selected_coin]
coin_average = self.V[selected_coin]
new_average = (coin_average * n + reward) / (n + 1)
N[selected_coin] += 1
self.V[selected_coin] = new_average
return rewards
if __name__ == "__main__":
import pandas as pd
import matplotlib.pyplot as plt
def main():
env = CoinToss([0.1, 0.5, 0.1, 0.9, 0.1])
epsilons = [0.0, 0.1, 0.2, 0.5, 0.8]
game_steps = list(range(10, 1010, 10))
result = {}
for e in epsilons:
agent = EpsilonGreedyAgent(epsilon=e)
means = []
for s in game_steps:
env.max_episode_steps = s
rewards = agent.play(env)
means.append(np.mean(rewards))
result["epsilon={}".format(e)] = means
result["count of coin toss"] = game_steps
result = pd.DataFrame(result)
result.set_index("count of coin toss", drop=True, inplace=True)
result.plot.line(figsize=(10, 5))
plt.show()
main()
|