学習メソッドtrainを実装します。前回実装した照会メソッドqueryと似ています。
重みをかけて発火させたあとに目標出力との誤差を算出しそれを学習率に応じて重みに反映する・・・これがニューラルネットワークの最重要ポイントかと思われます。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
| import numpy
import scipy.special
class neural_network:
def __init__(self, in_node, hid_node, out_node, learn_rate):
self.in_node = in_node
self.hid_node = hid_node
self.out_node = out_node
self.learn_rate = learn_rate
self.weight_in_hid = numpy.random.normal(0.0, pow(self.hid_node, -0.5), (self.hid_node, self.in_node))
''' ↓こんな感じの配列ができる
[[ 0.37395332 0.07296579 0.36696637]
[-0.1570748 0.28908756 0.99958053]
[-0.09054778 -0.20084478 0.31981826]]
'''
self.weight_hid_out = numpy.random.normal(0.0, pow(self.out_node, -0.5), (self.out_node, self.hid_node))
''' ↓こんな感じの配列ができる
[[ 0.93304259 0.02641947 0.29506316]
[-0.74275445 0.9010841 -0.47840667]
[ 0.04494529 0.49177323 1.13985481]]
'''
self.activation_func = lambda x: scipy.special.expit(x)
def train(self, in_list, target_list):
in_matrix = numpy.array(in_list, ndmin=2).T
target_matrix = numpy.array(target_list, ndmin=2).T
hid_in = numpy.dot(self.weight_in_hid, in_matrix)
hid_out = self.activation_func(hid_in)
final_in = numpy.dot(self.weight_hid_out, hid_out)
final_out = self.activation_func(final_in)
out_err = target_matrix - final_out
hid_err = numpy.dot(self.weight_hid_out.T, out_err)
self.weight_hid_out += self.learn_rate * numpy.dot((out_err * final_out * (1.0 - final_out)), numpy.transpose(hid_out))
self.weight_in_hid += self.learn_rate * numpy.dot((hid_err * hid_out * (1.0 - hid_out)), numpy.transpose(in_matrix))
def query(self, input_list):
in_matrix = numpy.array(input_list, ndmin=2).T
hid_in = numpy.dot(self.weight_in_hid, in_matrix)
hid_out = self.activation_func(hid_in)
final_in = numpy.dot(self.weight_hid_out, hid_out)
final_out = self.activation_func(final_in)
return final_out
|
これで自作ニューラルネットワークが完成しました。
このクラスを使ってMNISTデータの判定を行ってみます。
まず、学習データ(100種類)とテストデータ(10種類)をダウンロードします。
1
2
| !wget https://raw.githubusercontent.com/makeyourownneuralnetwork/makeyourownneuralnetwork/master/mnist_dataset/mnist_test_10.csv
!wget https://raw.githubusercontent.com/makeyourownneuralnetwork/makeyourownneuralnetwork/master/mnist_dataset/mnist_train_100.csv</pre>
|
データを読み込んで、どんなデータか表示してみます。
1
2
3
4
5
6
7
8
9
10
| import numpy
import matplotlib.pyplot
%matplotlib inline
with open('mnist_train_100.csv', 'r') as f:
data_list = f.readlines()
val = data_list[7].split(',')
img = numpy.asfarray(val[1:]).reshape((28, 28))
matplotlib.pyplot.imshow(img, cmap='Greys', interpolation='None')
|
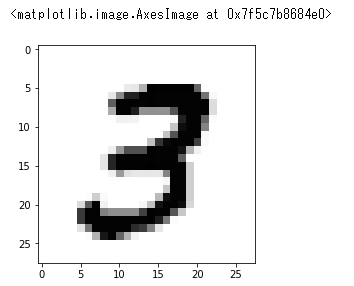
データを学習し、テストデータの1つを選んでどの数字と合致する確率が高いかを表示します。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
| import numpy
import matplotlib.pyplot
%matplotlib inline
in_node = 784
hid_node = 200
out_node = 10
learn_rate = 0.2
n_network = neural_network(in_node, hid_node, out_node, learn_rate)
with open('mnist_train_100.csv', 'r') as f:
train_data = f.readlines()
epochs = 10
for e in range(epochs):
for record in train_data:
val = record.split(',')
in_data = (numpy.asfarray(val[1:]) / 255.0 * 0.99) + 0.01
target = numpy.zeros(out_node) + 0.01
target[int(val[0])] = 0.99
n_network.train(in_data, target)
with open('mnist_test_10.csv', 'r') as f:
test_data = f.readlines()
val = test_data[0].split(',')
img = numpy.asfarray(val[1:]).reshape((28, 28))
matplotlib.pyplot.imshow(img, cmap='Greys', interpolation='None')
res = n_network.query((numpy.asfarray(val[1:]) / 255.0 * 0.99) + 0.01)
for a,b in enumerate(res):
print('{}の可能性 {:5.2f}%'.format(a,b[0] * 100))
|
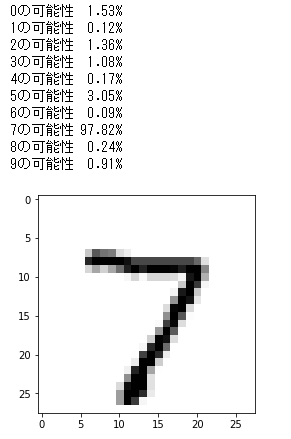
今回は[7]の合致率が97%以上ときちんと認識しているようです。
10種類あるテストデータをすべて試してみましたが、なかなかよい結果がでてました。
ただ人間でもよくわからないデータ(手書き数字)だとはっきり認識するのは難しいようです。(あたり前か・・・)
隠れ層のノード数、学習率、学習回数の範囲をいろいろ試してみて認識率がどうかわるかを試すのもよいかと思います。
(Google Colaboratoryで動作確認しています。)