大規模なデータセットの視覚化
Datashaderは、大規模なデータセットを高速に視覚化するためのPythonライブラリです。
HoloViewsは、Datashaderと統合されていて容易に扱うことができます。
Plotly では数十万のデータを処理できますが、Datashader では数千万から数億のデータを処理できます。
Datashader では、データセット全体ではなく、データセットをラスタライズ(複雑なデータを軽くてシンプルなデータに)して扱います。
サンプルコード
今回は、plotly.pyに含まれる irisデータセットを読み込み、ノイズを追加して150万個のデータ(DataFrame) を生成します。(14行目)
この大規模なデータ(DataFrame)を、HoloViews Datasetにラップします。(16行目)
[ソースコード]
1 | import dash |
[ブラウザで表示]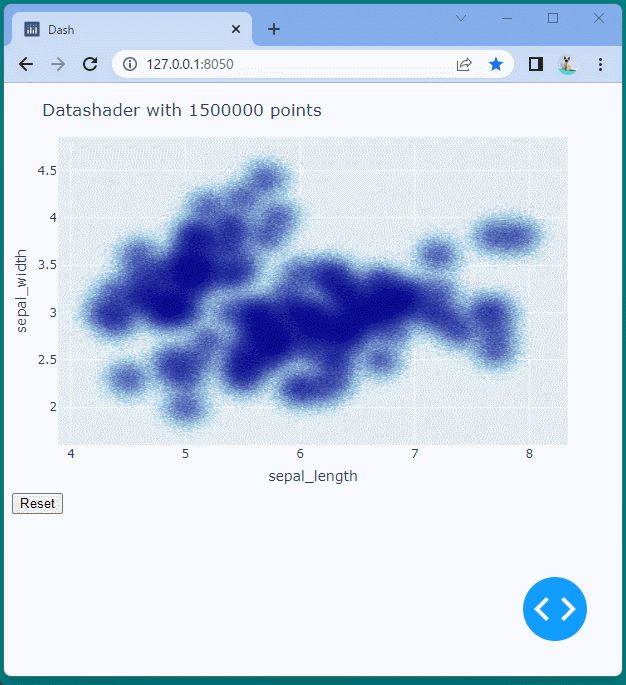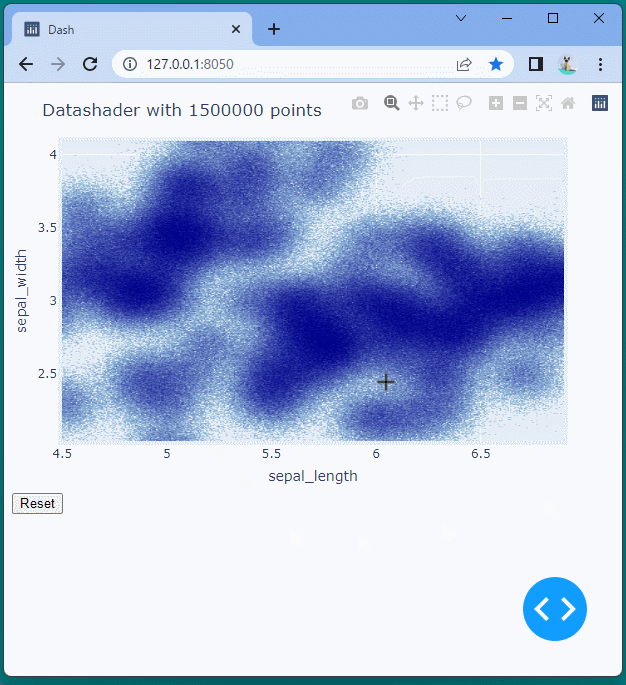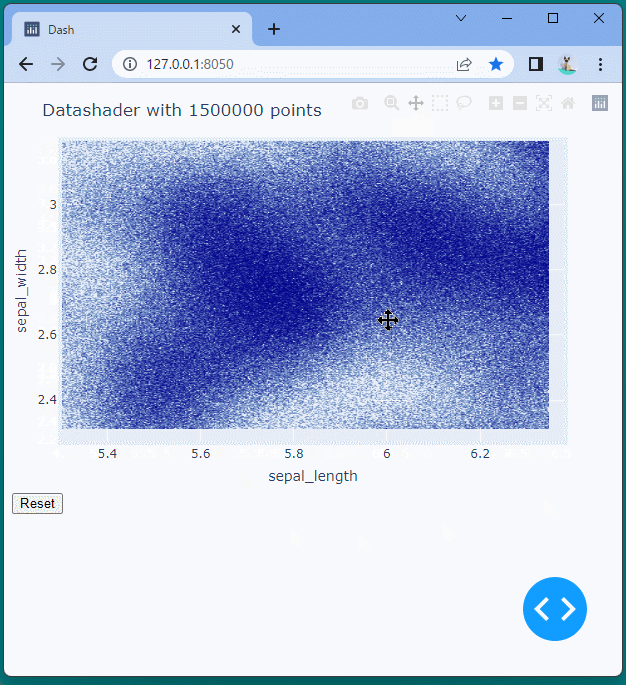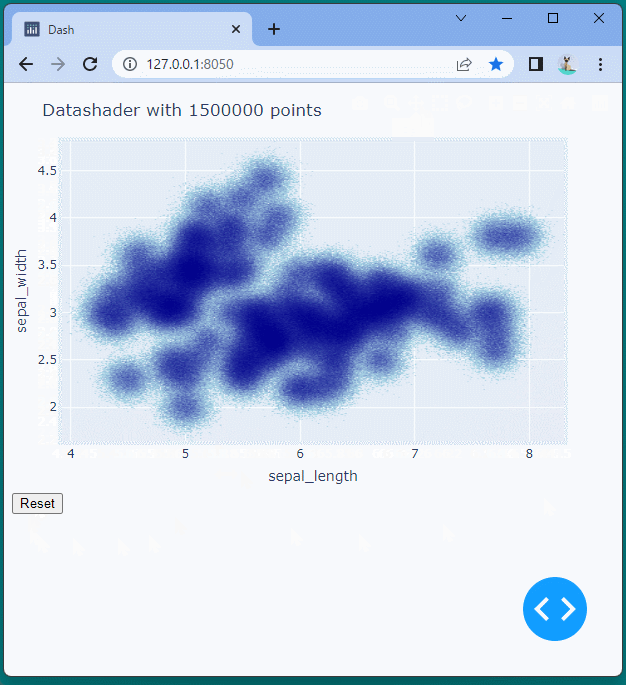
150万個のデータを散布図で表示することができました。
データの表示範囲を変更したり、ドラッグやスクロールで移動や拡大・縮小を行ってももたつくことなくスムーズに表示できることが確認できます。