ハイパーパラメータで生成する決定木の数を変更してみます。
決定木の数を変更
n_estimatorsの値を10→3に変更し、ランダムフォレストのモデルを構築します。
[Google Colaboratory]
1 | rf_change_param = RandomForestRegressor(n_estimators=3, max_depth=20, random_state=0).fit(X_train,y_train) |
[実行結果]
残差プロット (n_estimators=3)
予測値を算出し、残差プロットを表示します。
[Google Colaboratory]
1 | y_train_pred = rf_change_param.predict(X_train) |
[実行結果]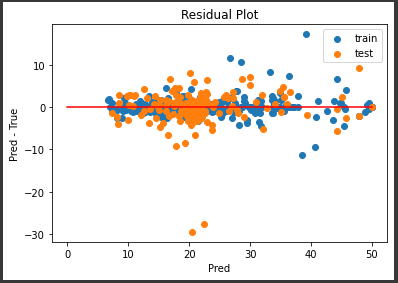
決定木の数が10本のときとあまり変化は見られません。
精度評価スコア (n_estimators=3)
精度評価スコアを表示します。
[Google Colaboratory]
1 | print("訓練データスコア") |
[実行結果]
決定木の数が10本(前回記事)のときとほぼ変わらない結果となっています。
基本的に決定木の数を増やしていくほど精度は上がっていきますが、その精度向上は徐々に収束していきます。
また、ランダムフォレストモデルでは対象データが膨大になったり、決定木の数や深さを増やすほど、処理時間が延びCPU負荷も増えますので注意が必要です。