Natural Language Processing with Disaster Tweetsrに関する2回目の記事です。
今回はツイート(text)に関するEDA(探索的データ解析)を行います。
ツイートの探索的データ解析
基本的なテキスト分析として次の3点を調べます。
- 文字数
- 単語数
- 平均単語レングス
まずは文字数をカウントしグラフ化します。
災害関連かどうかでグラフを分けています。
[ソース]
1 | fig,(ax1,ax2)=plt.subplots(1,2,figsize=(10,5)) |
[結果]
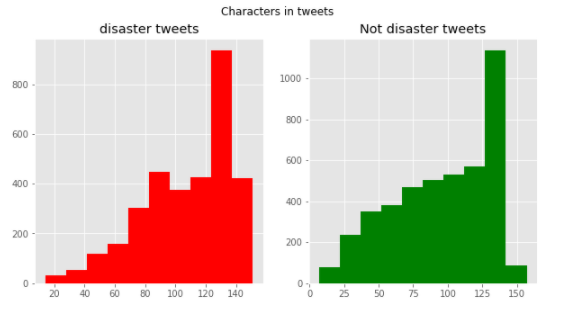
両グラフともほとんど同じ分布になっています。
120語から140語付近がもっとも度数が多いようです。
次に、単語数をカウントしグラフ化します。
[ソース]
1 | fig,(ax1,ax2)=plt.subplots(1,2,figsize=(10,5)) |
[結果]
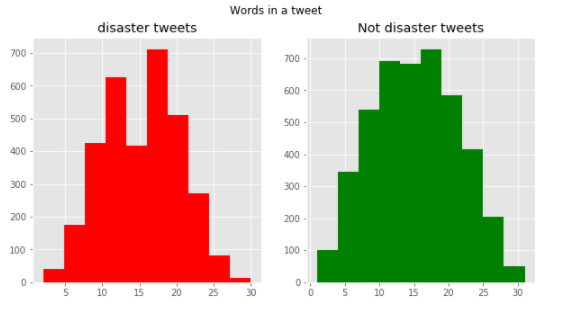
こちらも似た分布にはなっていますが、単語数15のところの災害関連ツイートが妙に少なくなっていることが分かります。
最後に、平均単語レングスをカウントしグラフ化します。
[ソース]
1 | fig,(ax1,ax2)=plt.subplots(1,2,figsize=(10,5)) |
[結果]
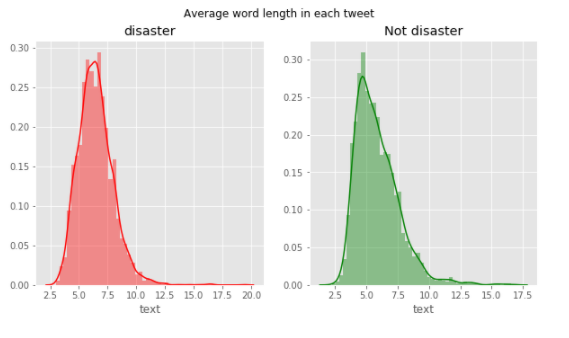
こちらもほぼ同じ分布になっているように見えます。
文字数、単語数、平均レングスでは災害関連かどうかを判断するのは難しいのかもしれません。
次回は語尾の単語や句読点、よく使われる単語などを調べていきます。