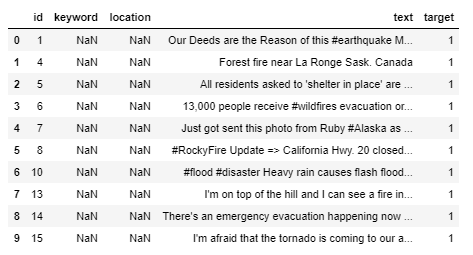
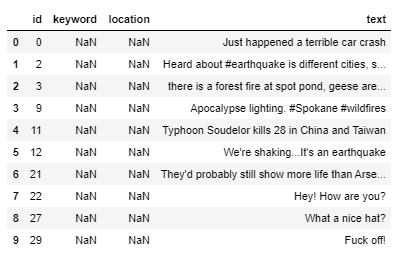
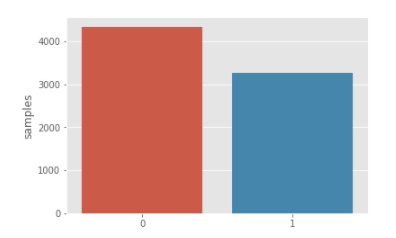
import os import pandas as pd import matplotlib.pyplot as plt import seaborn as sns import numpy as np from nltk.corpus import stopwords from nltk.util import ngrams from sklearn.feature_extraction.text import CountVectorizer from collections import defaultdict from collections import Counter plt.style.use('ggplot') stop=set(stopwords.words('english')) import re from nltk.tokenize import word_tokenize import gensim import string from keras.preprocessing.text import Tokenizer from keras.preprocessing.sequence import pad_sequences from tqdm import tqdm from keras.models import Sequential from keras.layers import Embedding,LSTM,Dense,SpatialDropout1D from keras.initializers import Constant from sklearn.model_selection import train_test_split from keras.optimizers import Adam