Pandas Profileというライブラリを使うと、数行のコードを書くだけでデータセットの概要や特徴量を決められたフォーマットで分かりやすく表示することができます。
Pandas Profileのアップデート
GoogleさんのColaboratoryでPandas Profileを実行するとバージョンの問題でエラーになるので、Pandas Profileをアップデートしておきます。
1 | !pip install -U pandas_profiling |
アップデート完了後に一旦ランタイムを再起動します。(Restart Runtimeボタンを押下)
Pandas Profileの実行
タイタニックのデータセットを読み込み、Pandas Profileを実行します。
なお、データ量の問題でメモリ不足のエラーが発生するので、いくつか不要そうな項目を削除しています。
1 | import seaborn as sns |
Pandas Profileの内容確認
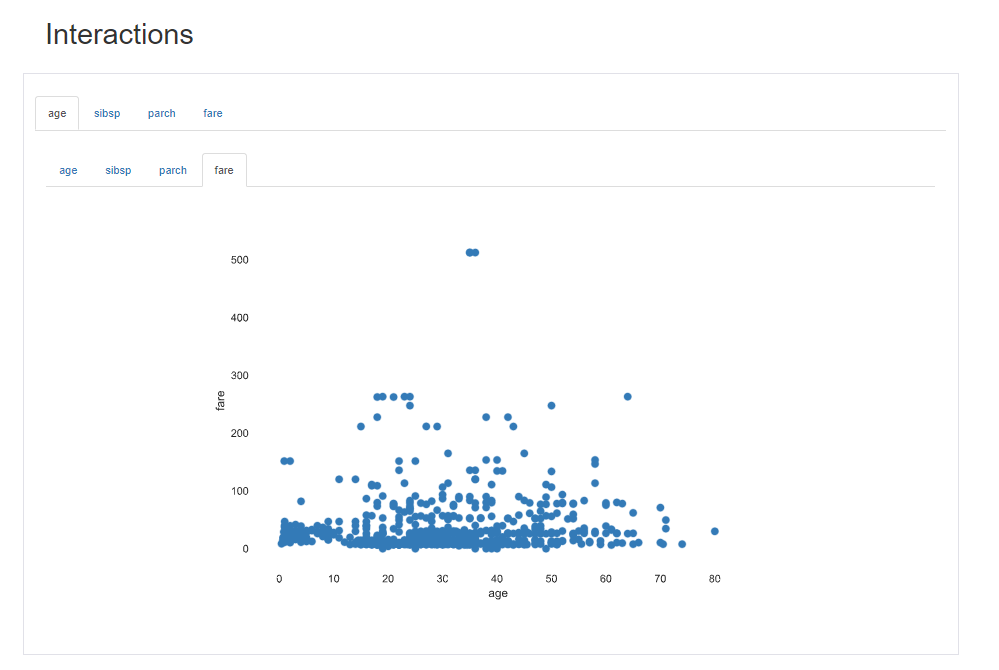
Overview項目では、データセットの概要を確認できます。
- 11列 891行のデータであること。
- 179の欠損値(Missing)があり、全体の1.8%であること。
- Variable Typesではカテゴリデータ(Categorical)が6項目、数値型(Numeric)が4項目、ブール型(Boolean)が1項目あること。
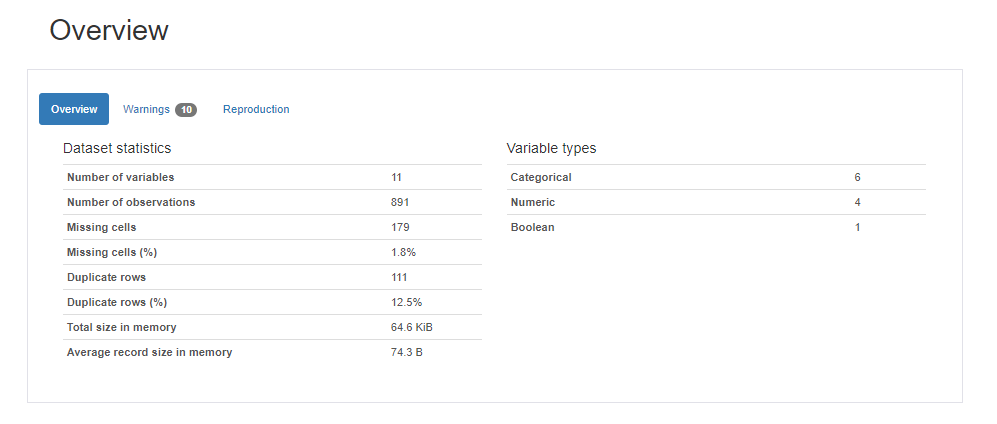
Variables項目では、各データ型に応じて統計量やヒストグラムが表示されます。
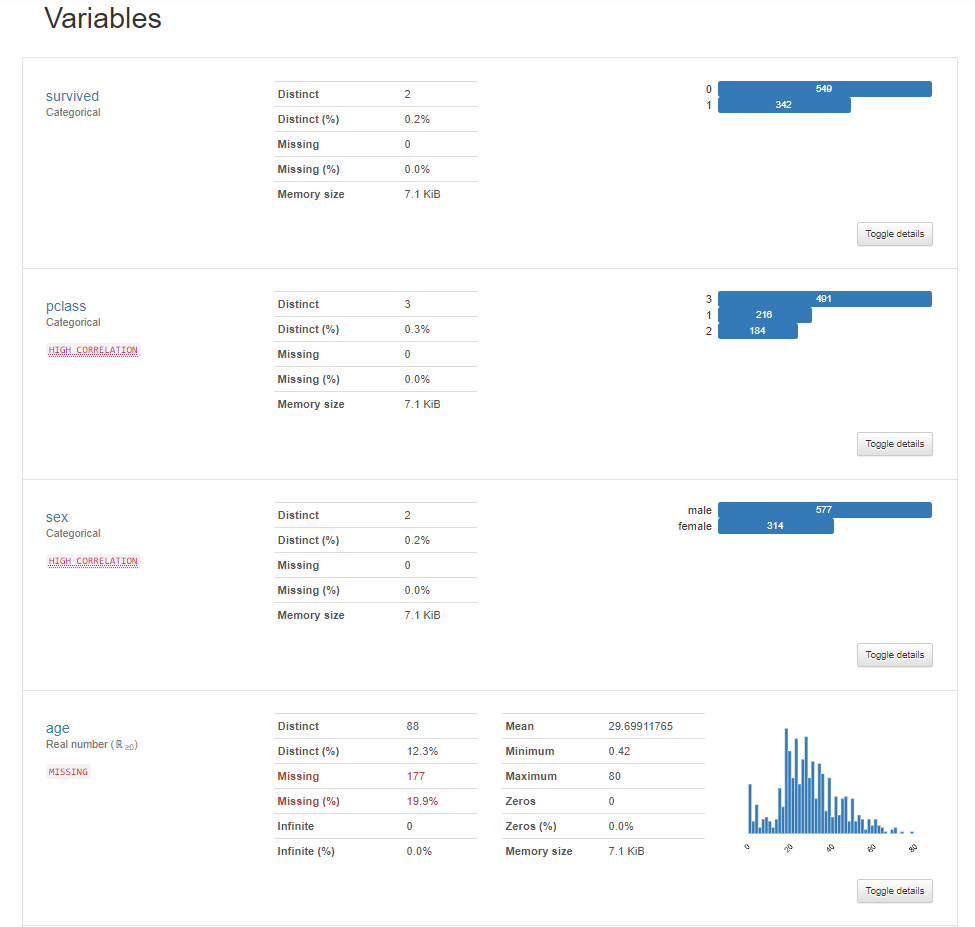
Toggle detailsボタンを押すと、さらに詳細なデータ(統計情報)が表示されます
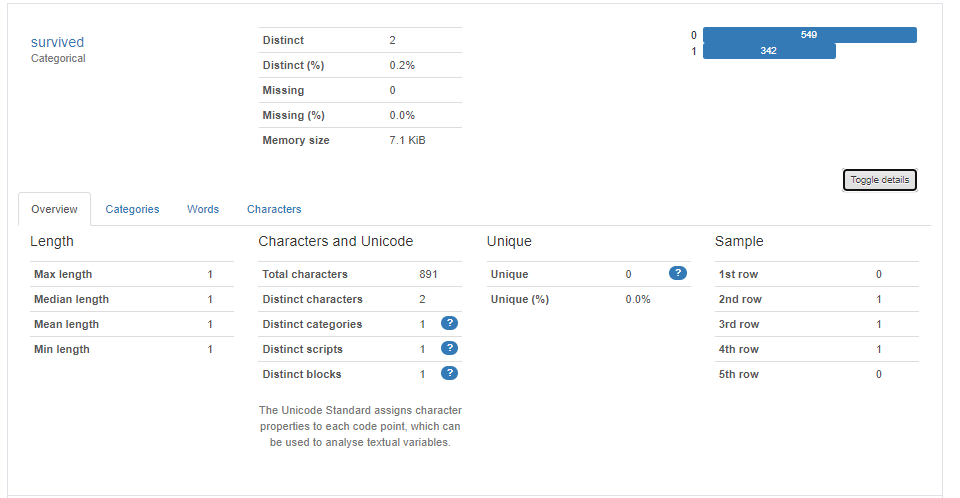
Interactions項目では、変数を指定し散布図を確認することができます。
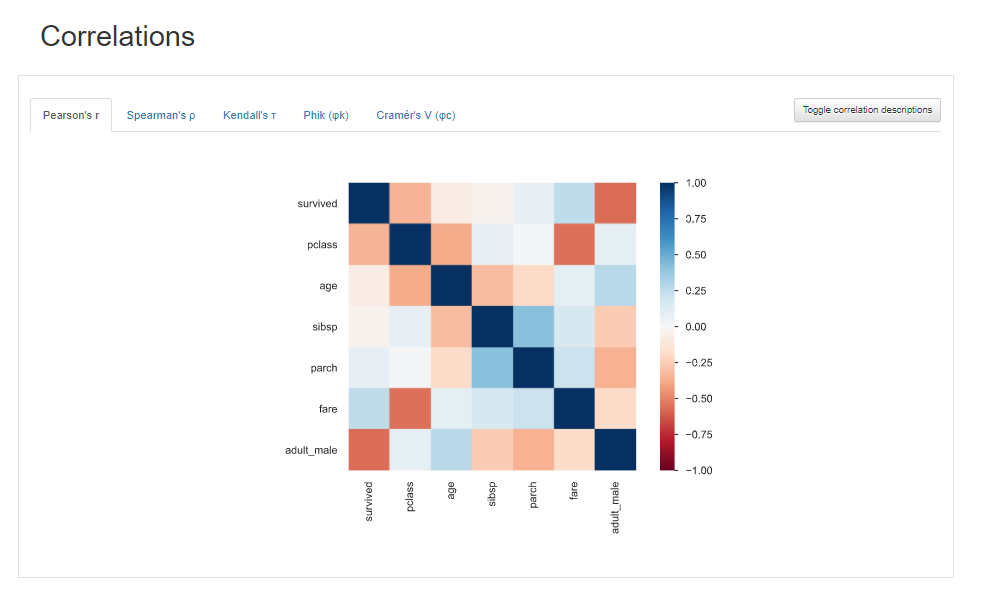
Correlations項目では、ヒートマップが表示されます。
ヒートマップは2変数間の相関係数の値を色にしたものであり、変数間の相関を一目でみることができます。
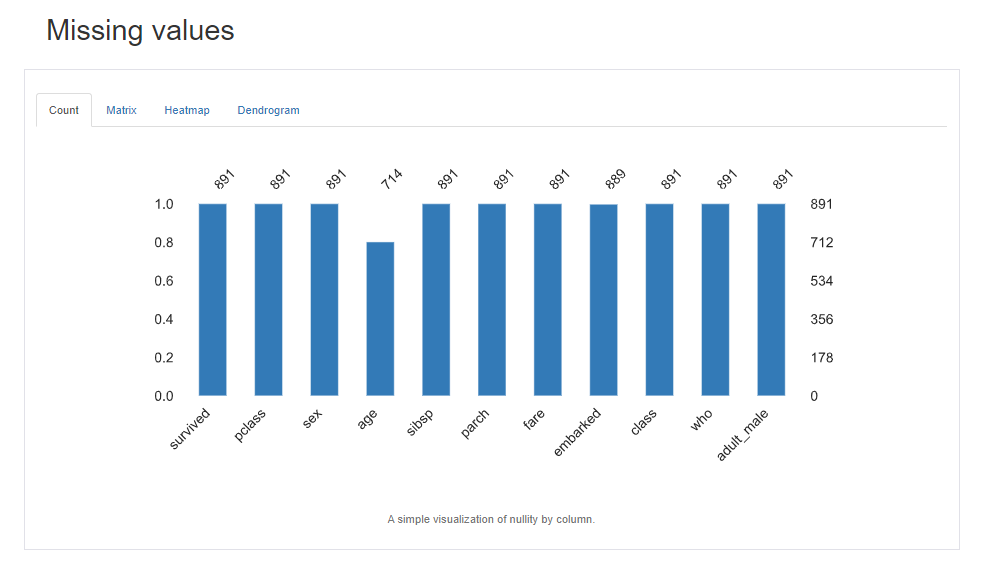
Missing Values項目では、欠損値の情報を見ることができます。
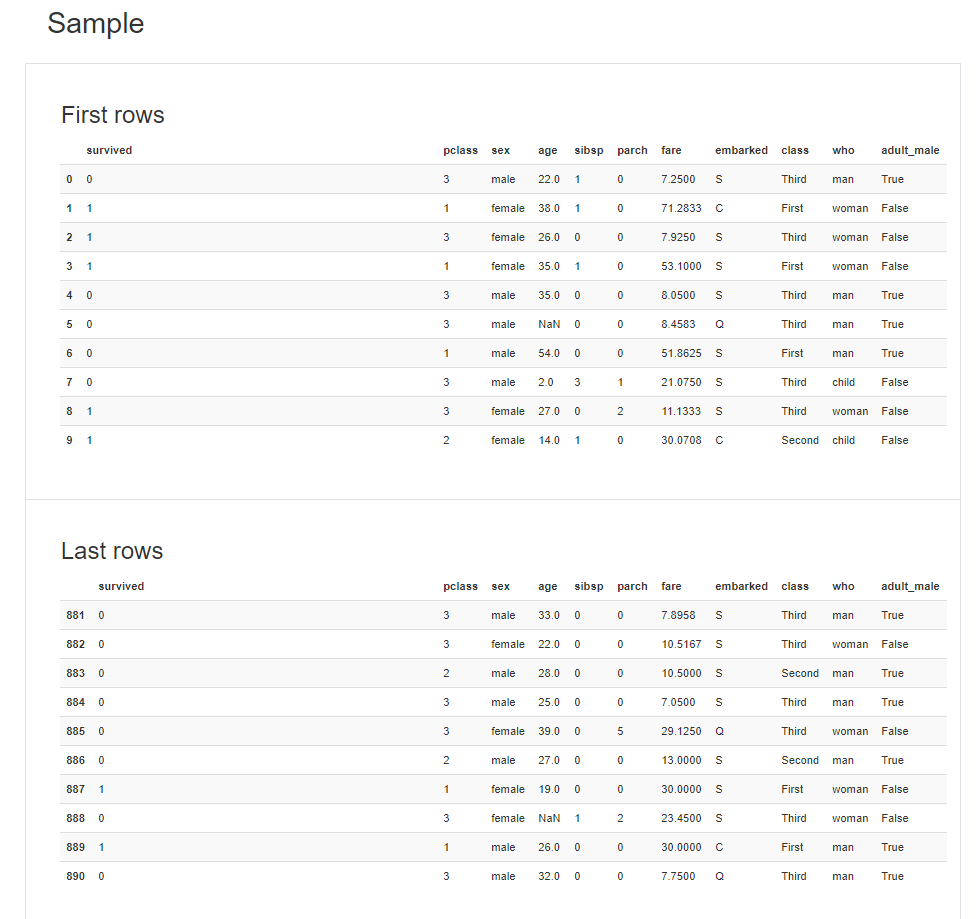
Samples項目では、先頭の10行と最後の10行が表示されます。
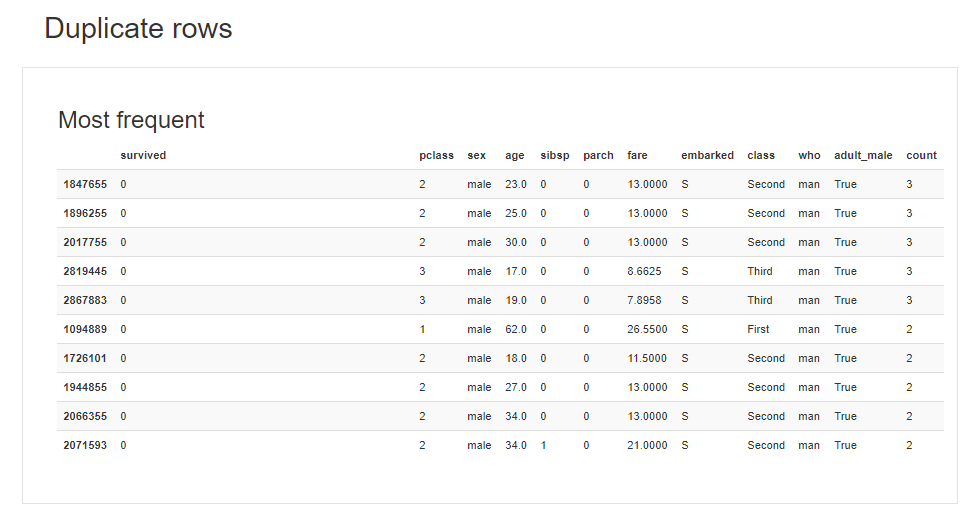
Duplication Rows項目では、重複行の情報を確認することができます。
Pandas Profileを使うと一気に各データの特徴を把握することができるので本当に便利ですね。
またto_file関数を使うと、ファイル出力(Html)できますのでプロファイリング結果を受け渡しする場合に有益かと思います。
1 | profile.to_file('Profiling.html') |
(実行環境としてGoogleさんのColaboratoryを使用ています。)